Troubleshooting encoding problems
This article is a detailed guide that aims to assist when debugging encoding issues that occur during implementation of Funnelback.
Overview
This page is a guide about troubleshooting encoding / charsets problems with Funnelback, where the symptom is usually odd or corrupted characters showing up in search results (titles, summaries or metadata).
There are no recipes for this kind of problems, so this page is more about discussing approaches and troubleshooting examples rather than step-by-step instructions. It should give you enough background to understand the problem and diagnose it by yourself.
What not to do
A quick fix that is often made is to write either a custom filter or a Groovy hook script to clean the output. That shouldn’t be done for multiple reasons:
-
It doesn’t address the root cause of the problem, and by doing so might hide other issues
-
Those filters are using a blacklist approach when only well-known odd characters are cleaned up. It’s bound to fail as new characters that weren’t thought of will appear in the content
-
In most cases there is no good replacement for those corrupted characters. Yes, you can replace a middle-dash with a simple dash, but replace the French é with a non-accented e, and you’ll find that words might now have different meanings.
Understanding the problem
This kind of corruption happens when different components of Funnelback are not talking with the same character encoding. One component can output ISO-8859-1, but Funnelback will read it as UTF-8.
Encoding and decoding is usually done at the boundary of each component. When a component write a file on disk (e.g. crawler), it uses a specific encoding. When another component reads this file back in (e.g. indexer), it assumes an encoding. If those components are not using the same encoding, corruption occurs.
So, to be able to pinpoint the problem, one must look at the boundaries of each component of Funnelback, and at the original source document:
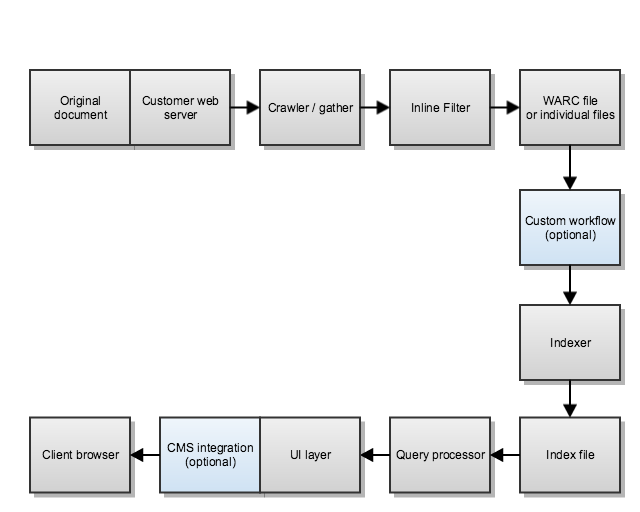
We can see that the content is following a complex lifecycle, from where it was downloaded from to being returned as a summary in a search results page. During this lifecycle, it crosses multiple boundaries that can each have an encoding problem.
The right way to diagnose an encoding issue it to look at each boundary in turn, and confirm that each component is doing the right thing.
Different ways of representing non-ASCII characters
The only safe characters that can be represented in all encodings are ASCII characters. i.e. A to Z in lower and upper case and some punctuation signs.
Representing non-ASCII characters can be achieved in different ways. Understanding those different ways is crucial to being able to diagnose encoding problems.
Using HTML character entities references
In an HTML document, special characters can be represented by entities, either:
-
Numeric entities:
&#nnn;. For example ç can be represented asç, 231 being the unicode code point of the c with cedilla -
Named entities:
&name;. For example, the same ç can be represented as&#ccedil;.
Those entities will need to be decoded to be displayed, or to process the content. For example the indexer doesn’t know what Français means, but it knows what Français does.
Note that the encoding (see below) of the document doesn’t matter in this case, because HTML entities are always expressed with ASCII characters (either numbers, or ASCII letters to compose entity names) so it doesn’t matter which encoding the document is in.
Using a different encoding in the content
Understanding encodings is the key to diagnosing that kind of problems.
The main idea is that different languages use different characters. ASCII can only express up to 128 characters, which is not enough for non-English languages. In order to express more characters, different encoding were invented. For example European languages might use ISO-8859, whereas Chinese could use Big5 and Japanese ShiftJIS. The only universal way to represent all characters of all languages is to use Unicode, and to represent Unicode characters in a document one must use one of its encodings/implementations such as UTF-8.
Some languages didn’t need a lot of additional characters (e.g. French). In this case, they simply extended the ASCII set by adding 128 characters. It means that those character sets will have at most 256 (0 to 255) possible characters, which fits in a single byte. That’s for example ISO-8859-1.
Some other languages (e.g. Chinese, Japanese …) needed a lot more of characters. Adding 128 would not work, so they added a lot more but then needed more than one byte to represent greater values (> 255). That’s why non ASCII characters, for example in UTF-8, are represented as 2 or more bytes. You see one character in the screen, but when you look at the bytes on disk, there are more than one byte.
To give an example, if the document is encoded using ISO-8859-1, the ç will be represented by a byte of value 231 (0xE7 in hexadecimal), whereas if encoded in UTF-8, it will be represented as 2 bytes, 0xC3 0xA7.
Content is "Test: ç" (followed by a new line)
$ hexdump -C iso.txt
00000000 54 65 73 74 3a 20 e7 0a |Test: ..|
00000008
$ hexdump -C utf8.txt
00000000 54 65 73 74 3a 20 c3 a7 0a |Test: ...|
00000009Note that the byte representation is the only thing that matters. An HTML document can claim to be encoded in ISO-8859-1 in its META tags, but it’s completely possible that the content is actually written as UTF-8 bytes. That’s usually the cause of most encoding problems.
For more information, see:
Diagnosis
Review content source
The first step is to look at the original content, as the crawler will see it, by making a simple HTTP request to the original web server.
With the old Squiz forums as use case, we can observe that it looks correct, we don’t see any corrupted characters in the output:
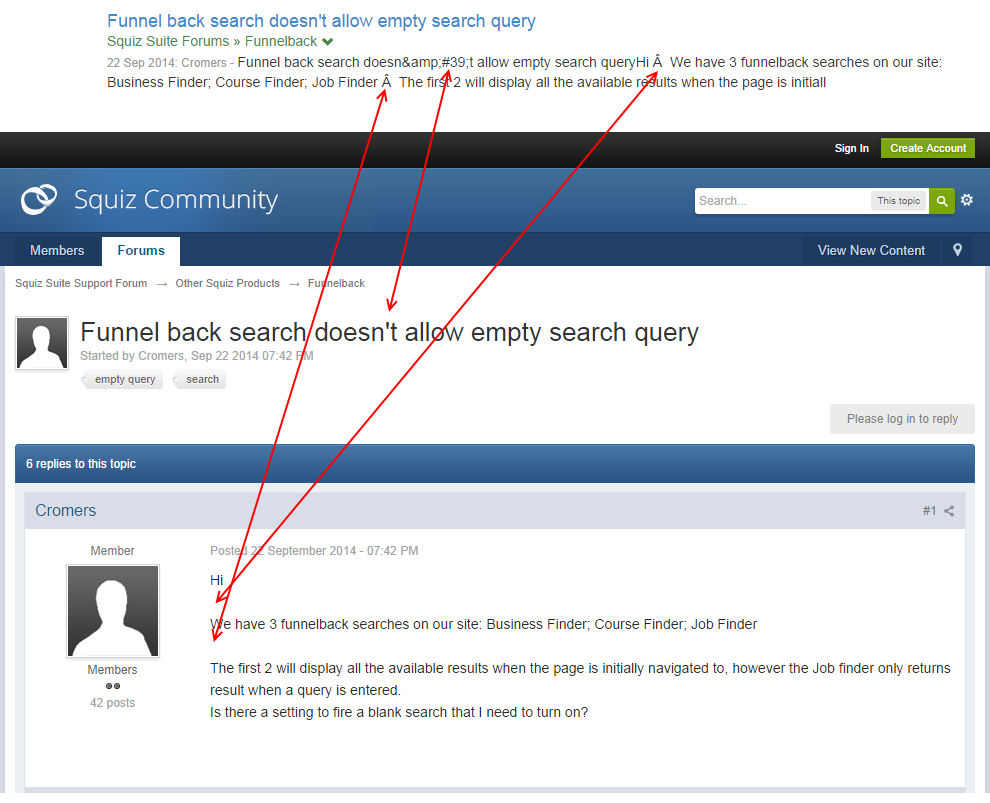
However, that doesn’t mean that the content is not problematic because browsers are usually smart (smarter than our crawler) and can automatically fix a number of encoding-related errors. Additionally, collecting more info on those corrupted characters will help us later.
The first thing to look at is the HTML source of the page, to see how those characters are represented:
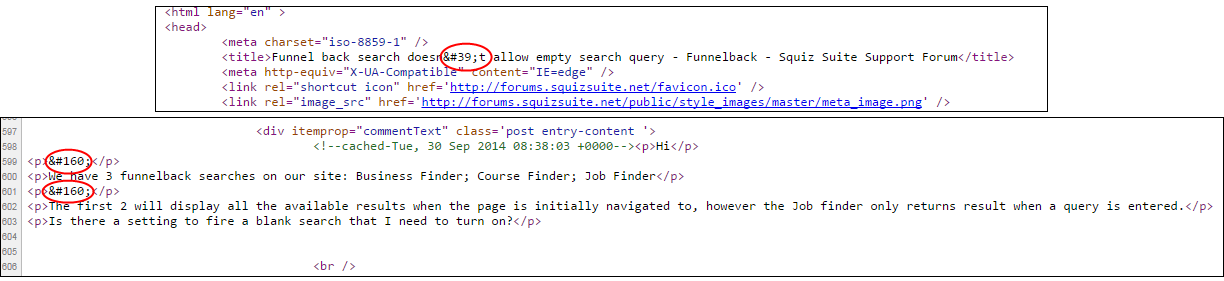
In this case those characters are represented as HTML entities. That’s perfectly valid and the entities used there are valid too. Looking at the list of HTML entities:
-
'is a regular quote -
 is a non-breaking space
This content seems ok.
Declared encoding of the document
Our use case seems to be related to processing entities, and so it’s probably not related to actual encoding problems on the original document. When that’s the case, other information is useful to lookup.
What is the encoding declared in the HTML source?
In our case it’s ISO-8859-1 as seen in the <meta charset="iso-8859-1"> tag.
What is the encoding returned by the webserver?
It can differ from what’s in the page, and that’s usually a source of problem.
To find out the encoding, use your browser developer tools and search for the Content-Type response header returned on the main HTTP request:
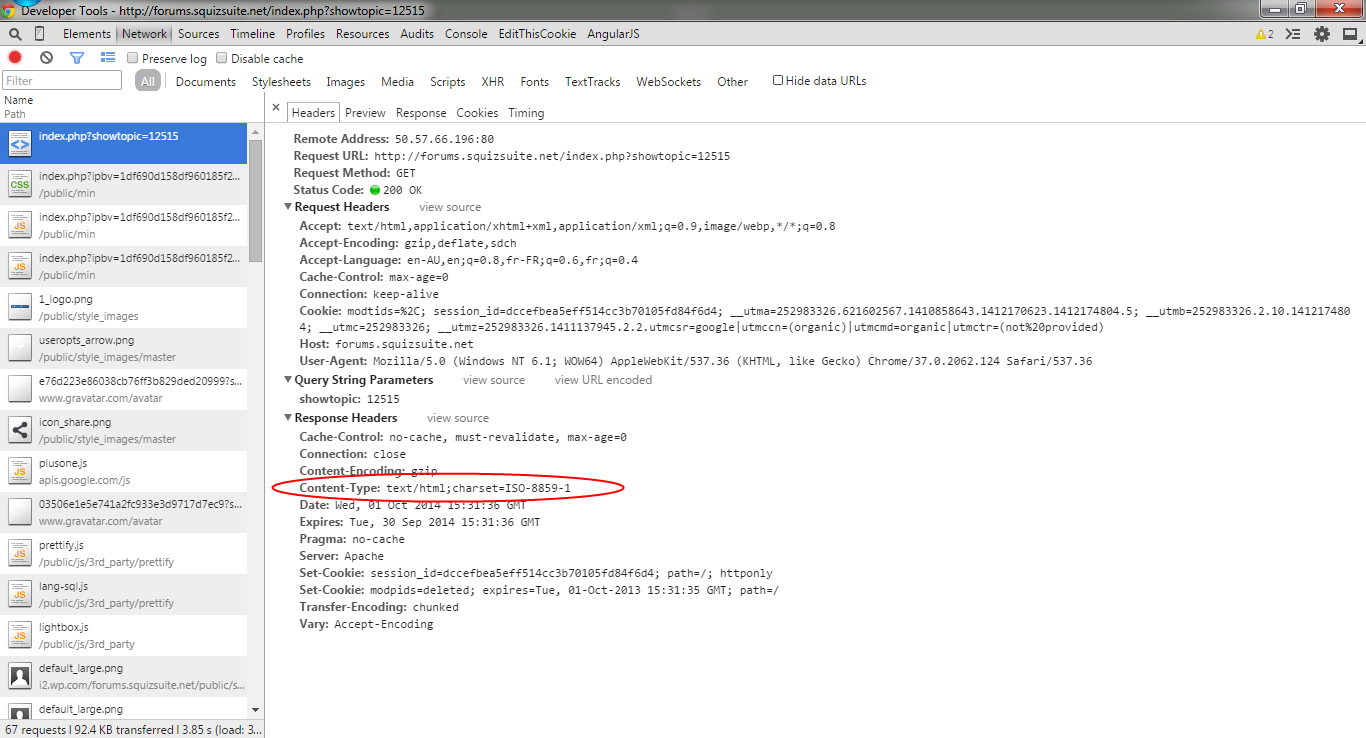
Alternatively, use wget (observe the Content-Type header at the bottom.
$ wget -S 'http://forums.squizsuite.net/index.php?showtopic=12515'
--2014-10-01 17:33:48-- http://forums.squizsuite.net/index.php?showtopic=12515
Resolving forums.squizsuite.net (forums.squizsuite.net)... 50.57.66.196
Connecting to forums.squizsuite.net (forums.squizsuite.net)|50.57.66.196|:80... connected.
HTTP request sent, awaiting response...
HTTP/1.1 200 OK
Date: Wed, 01 Oct 2014 15:33:48 GMT
Server: Apache
Set-Cookie: session_id=df2a0d03ae9572592471d1109e0942e0; path=/; httponly
Set-Cookie: modpids=deleted; expires=Tue, 01-Oct-2013 15:33:47 GMT; path=/
Cache-Control: no-cache, must-revalidate, max-age=0
Expires: Tue, 30 Sep 2014 15:33:48 GMT
Pragma: no-cache
Connection: close
Transfer-Encoding: chunked
Content-Type: text/html;charset=ISO-8859-1
Length: unspecified [text/html]In our case, the Content-Type returned by the server and the Content-Type declared in the page match. Sometimes they don’t because the content author usually doesn’t control the webserver. When they don’t match, browser will use various heuristics to try to find the right one. The Funnelback crawler will follow an order of precedence.
What is the actual encoding of the page?
Despite encoding values being returned by the web server and/or the page META tags, it’s possible that both of them are lying and that the content is actually encoded differently. The only way to find that out is to use an hexadecimal editor, and to inspect the content at the byte level to see how it’s actually encoded. In our specific case it doesn’t matter because special characters are encoded as entities, but that’s something you always need to confirm.
Consider the following HTML document. If you look at it’s byte representation, you’ll see that the ç is represented with 2 bytes 0xC3 0xA7. That’s actually UTF-8, not ISO-8859-1.
If the page was encoded in ISO-8859-1 as it claims, it should have been a single 0xE7 byte.
===== Character encoding example
<!doctype html>
<html lang=en-us>
<head><meta charset="iso-8859-1"></head>
<body>Parlons Français</body>
</html>Incorect Output: Byte representation of HTML Character encoding example.
$ hexdump -C wrong.html
00000000 3c 21 64 6f 63 74 79 70 65 20 68 74 6d 6c 3e 0a |<!doctype html>.|
00000010 3c 68 74 6d 6c 20 6c 61 6e 67 3d 65 6e 2d 75 73 |<html lang=en-us|
00000020 3e 0a 3c 68 65 61 64 3e 3c 6d 65 74 61 20 63 68 |>.<head><meta ch|
00000030 61 72 73 65 74 3d 22 69 73 6f 2d 38 38 35 39 2d |arset="iso-8859-|
00000040 31 22 3e 3c 2f 68 65 61 64 3e 0a 3c 62 6f 64 79 |1"></head>.<body|
00000050 3e 50 61 72 6c 6f 6e 73 20 46 72 61 6e c3 a7 61 |>Parlons Fran..a|
00000060 69 73 3c 2f 62 6f 64 79 3e 0a 3c 2f 68 74 6d 6c |is</body>.</html|
00000070 3e 0a |>.|
00000072Correct Output: Byte representation of HTML Character encoding example with
$ hexdump.exe -C good.html
00000000 3c 21 64 6f 63 74 79 70 65 20 68 74 6d 6c 3e 0a |<!doctype html>.|
00000010 3c 68 74 6d 6c 20 6c 61 6e 67 3d 65 6e 2d 75 73 |<html lang=en-us|
00000020 3e 0a 3c 68 65 61 64 3e 3c 6d 65 74 61 20 63 68 |>.<head><meta ch|
00000030 61 72 73 65 74 3d 22 69 73 6f 2d 38 38 35 39 2d |arset="iso-8859-|
00000040 31 22 3e 3c 2f 68 65 61 64 3e 0a 3c 62 6f 64 79 |1"></head>.<body|
00000050 3e 50 61 72 6c 6f 6e 73 20 46 72 61 6e e7 61 69 |>Parlons Fran.ai|
00000060 73 3c 2f 62 6f 64 79 3e 0a 3c 2f 68 74 6d 6c 3e |s</body>.</html>|
00000070 0a |.|
00000071Web crawler, WARC file
Assuming that we know the content is good and properly served by the customer website, we need to look at the crawler. The crawler will download the content, process it in some way, pass it to the the filtering layer, and store it in the WARC file.
-
There’s not much to look at on the crawler itself, in the logs you’ll just get the HTTP response headers, similar to what was achieved with wget earlier.
-
There’s not much to look at on the filters either, because they don’t log much information by default. Moreover, debugging filters is a bit difficult as you need to add relevant log statements to your custom Groovy code.
-
That’s why usually one looks at the WARC file first. If the content is correct in the WARC file, we’ll know that the problem lies elsewhere, but if it’s not we’ll know that we’ll have to dig into the crawler and filter.
Extracting content from the WARC file
Depending on your Funnelback version, you’ll either have to use warc.pl (up to v13) or WarcCat (v14 and above).
Looking at the extracted content, we can see something interesting: The HTML numeric entity in the title has been converted to a named entity:
$ $SEARCH_HOME/linbin/java/bin/java -classpath "lib/java/all/*" com.funnelback.warc.util.WarcCat -stem data/squiz-forum-funnelback/live/data/funnelback-web-crawl -matcher MatchURI -MF "uri=http://forums.squizsuite.net/index.php?s=6258edbbc08a5347636117c80372a804&showtopic=12515" -printer All > /tmp/content.txtExample extracted content as html:
...
<title>Funnelback search doesn't allow empty search query - Funnelback - Squiz Suite Support Forum</title>
...While surprising, that’s not necessarily unexpected as the filters can do that especially when parsing HTML with JSoup. In any case, that’s still valid HTML and valid entities.
Regarding the line breaks after Hi, the numeric entities seems to have disappeared from the HTML source.
However, if we fire up our trusty hex editor, we can actually see what happened behind the scenes.
HTML source:
...
<p>Hi</p>
<p> </p>
<p>We have 3 funnelback searches on our site: Business Finder; Course Finder; Job Finder</p>
<p> </p>
...Hex of HTML source:
00006ca0 20 20 20 20 20 20 20 3c 70 3e 48 69 3c 2f 70 3e | <p>Hi</p>|
00006cb0 20 0a 20 20 20 20 20 20 20 20 20 20 20 3c 70 3e | . <p>|
00006cc0 c2 a0 3c 2f 70 3e 20 0a 20 20 20 20 20 20 20 20 |..</p> . |
00006cd0 20 20 20 3c 70 3e 57 65 20 68 61 76 65 20 33 20 | <p>We have 3 |Observe that what is between the opening and closing P tags is 0xC2 0xA0. This is the UTF-8 representation for the non breaking space, which was previously represented as the   named entity.
So here, we’ve actually found one problem: The page is still declared as ISO-8859-1, but non-breaking spaces are represented as a UTF-8 sequences. Because the declared encoding is ISO-8859-1 it is likely PADRE will index the document with this encoding. Instead of interpreting 0xC2 0xA0 as a single UTF-8 character (non-breaking space), it will interpret it as 2 separate ISO-8559-1 characters, with:
-
0xC2= 194 = Â -
0xA0= 160 = non breaking space
That explains why a  is showing up in the results!
It’s likely to be caused by a filter, because the crawler by itself doesn’t modify the content. The only way to fix that is to pinpoint which filter is causing the problem.
Filters
When the content stored in the WARC file is incorrect, it’s likely to be because of a misbehaving filter. Filters needs to preserve encoding when reading or writing content.
Troubleshooting filters is hard: It might be single filter at the origin of the problem, or multiple of them. What a filter is doing can be undone by another filter in the chain, etc. Some tips to help diagnosing the problem:
-
It’s often easier to try to reproduce the problem on a separate data source, with only a single document causing the problem. This way the turnaround time is faster, and the logs are easier to read.
-
Do not necessarily trust log files, or your terminal. Logs are written with a specific encoding. Similarly, your terminal display content in a specific encoding as well. Depending on the fonts installed on your systems, some characters might not show up even if they’re present in the content
-
If possible, try to add code to write the actual bytes that are being processed to a temporary file. You can then inspect this temporary file with an hex editor to remove any other factor (log file encoding, terminal fonts, etc.).
-
Be careful to write with bytes and not strings, because when manipulating strings you need to know the encoding of it to correctly interpret the bytes.
Determine the filter that is causing problems
The first step is to determine which filter(s) are causing the corruption. This is done by editing the filter.classes parameter in the data source configuration, removing all the filters, and then adding them back one by one:
In the data source configuration:
# Original
filter.classes=TikaFilterProvider,ExternalFilterProvider:DocumentFixerFilterProvider:InjectNoIndexFilterProvider:com.funnelback.services.filter.MetaDataScraperFilter
# In our case we know our document is HTML so it won't be processed by Tika, nor the ExternalFilterProvider so we can rule those out
filter.classes=DocumentFixerFilterProvider
filter.classes=DocumentFixerFilterProvider:InjectNoIndexFilterProvider
filter.classes=DocumentFixerFilterProvider:InjectNoIndexFilterProvider:com.funnelback.services.filter.MetaDataScraperFilterYou need to run an update between each change, to cause the content to be re-crawled and re-filtered.
In my case I found that MetaDataScraperFilter is causing the problem. It’s a Groovy filter living in lib/java/groovy.
Content reading
Browsing the source code, we can see that this filter converts the HTML content into a JSoup object, to be able to manipulate the HTML. While doing so, it tries to detect the charset of the document:
Let’s print this charset by using a logger, and inspect the crawler.log (or crawler.central.log, crawler.inline-filtering.log for older versions).
jsoup filter example:
//Converts the String into InputStream
InputStream is = new ByteArrayInputStream(input.getBytes());
BufferedInputStream bis = new BufferedInputStream(is);
bis.mark(Integer.MAX_VALUE);
//Get the character set
String c = TextUtils.getCharSet(bis);
bis.reset();
//Create the JSOUP document object with the calculated character set
Document doc = Jsoup.parse(bis, c, address);
doc.outputSettings().escapeMode(EscapeMode.xhtml);crawler.central.logDetected charset for http://forums.squizsuite.net/index.php?s=fb30266e34222a354db54c6e63c51aea&showtopic=12515: Windows-1252Charset is detected as Windows-1252, which is equivalent to ISO-8859-1 for our purposes (see the Indexer section below for further explanation), so that looks correct.
However, despite the charset detection being correct the content is still read wrong. That’s because of:
InputStream is = new ByteArrayInputStream(input.getBytes());The call to input.getBytes() used to convert the content string to an array of bytes doesn’t specify a charset so it will use the default one as said in the Javadoc. The default encoding in Funnelback is UTF-8. It means that the detected charset of the content will be Windows-1252 but the byte stream will be read as UTF-8 resulting in corruption.
This corruption is only visible when the string is written back, making the problem harder to diagnose.
One should always be careful when converting Strings to byte arrays String.getBytes() and vice-versa new String(byte[] data. If the charset is not specified it will use a default which might not necessary be what you want. (Usually UTF-8, but that’s platform dependent unless specified with a command line argument when starting the JVM). It’s better to always specify the charset to avoid any problems:
-
String.getBytes("Windows-1251") -
new String(data, "Windows-1251")
This specific code is not easy to fix because an InputStream is needed to detect the charset, but you need the charset to create the InputStream from the String! A better way to do it is to build the JSoup object from the input string itself. This way you need not to worry about providing an encoding with an InputStream .
Document doc = Jsoup.parse(input, address);
doc.outputSettings().escapeMode(EscapeMode.xhtml);Content writing
The content reading is wrong here, but for this guide sake let’s inspect how the content is written back:
doc.html();It’s simply using the JSoup Document.html() method to do so. We need to dig into the JSoup documentation to understand what charset will be used by this method. By doing so, we find the Document.OutputSettings class.
Let’s add some code to inspect the charset from the output settings just before writing the document:
logger.info("Output settings charset:" + doc.outputSettings().charset())
return doc.html();Inspecting the crawler.central.log:
2014-10-03 21:55:04,235 [com.funnelback.crawler.NetCrawler 0] INFO filter.MetaDataScraperFilter - Detected charset for http://forums.squizsuite.net/index.php?s=44a3483b0fde4fdef17c34532a5a9724&showtopic=12515: Windows-1252
2014-10-03 21:55:04,294 [com.funnelback.crawler.NetCrawler 0] INFO filter.MetaDataScraperFilter - Output settings charset:windows-1252That’s the correct charset, but we can still confirm that something is wrong in the filter by outputting the content before and after filtering, and compare both:
logger.info("Output settings charset:" + doc.outputSettings().charset())
logger.info("Raw content for "+address+": \n\n"+ input +"\n\n")
logger.info("Content for "+address+": \n\n" + doc.html() + "\n\n")Before:
<p>Hi</p>
<p> </p>
<p>We have 3 funnelback searches on our site: Business Finder; Course Finder; Job Finder</p>
<p> </p>After:
<p>Hi</p>
<p>Â </p>
<p>We have 3 funnelback searches on our site: Business Finder; Course Finder; Job Finder</p>
<p>Â </p>Custom workflow scripts
On non web data sources it’s common to have custom workflow scripts to process the content which is usually stored in individual files (often XML).
-
If the content was gathered using Funnelback components they all produce UTF-8. The custom workflow scripts need to read them back as UTF-8, and to write them as UTF-8 as well.
-
If the content was gathered by a custom mean, you need to know what encoding was used when the files were stored on disk
It’s crucial to preserve the correct encoding when processing content with workflow script. If you read it wrong, or write it wrong the data will get corrupted, and the rest of the chain (indexing, query processing, etc…) will produce corrupted output.
Make sure you check the result of your workflow script in isolation to confirm that the processed files were saved with the right encoding. If it’s XML files, try to open them in your browser to confirm they’re valid and display correctly.
Finding which encoding was used to store the content
There’s no easy way to automagically find the encoding of a file so it’s better to know what encoding was used by the custom gather component. However, you can get some clues by looking at the content itself.
-
Try to pinpoint a special character in the content like an accented letter or a Chinese / Japanese symbol. Open it with a hex editor, and observe how it is represented at the bytes level.
-
You can then try to locate the character in the ISO-8859-1 codepage layout or on websites like http://www.fileformat.info/ which will give you the UTF-8 representation.
-
As an example, if é is represented as a single byte of value 233 (
0xE9in hex), it’sISO-8859-1. If it’s represented as two bytes0xC3 0xA9, it’sUTF-8.
Ensuring your workflow script reads and writes it right
This is highly dependent of the language used to implement workflow scripts. Usually API calls to read or write files will allow you to specify an encoding.
When using Groovy there are different ways to configure the encoding:
-
Use the
-Dfile.encoding=…flag when starting Groovy. With this flag you can specify the encoding to use in the script without having to specify it for each read / write call -
Alternatively, specify the encoding when reading a file using
File.getText()orFile.withReader(), and similarly when writing files:new File("/tmp/test.txt").getText("ISO-8859-1") new File("/tmp/test.txt").withReader("ISO-8859-1") { reader -> ... } new File("/tmp/test.txt").append("hello", "ISO-8859-1")
Indexer
The indexer will tell you which encoding it used to interpret the content. That can be found in the Step-Index.log file where there’s one line for each indexed document:
Step-index.log:
{3 Windows-1252 HTML 84014 0 "acdehistuvADISU" 2014-09-22 263 [ T=14.000 W=695.000 Z=1.456 H=5.669 F=0.253 C=0.112 L=3.973 D=60.000 M=1.151 ] html}
URL: http://forums.squizsuite.net/index.php?showtopic=12515In our case PADRE used the Windows-1252 encoding, which can be considered equivalent to ISO-8859-1 (PADRE actually uses Windows-1252 instead of ISO-8859-1 for legacy reasons). It’s a bit misleading but PADRE is doing the right thing here by correctly detecting the encoding. If it had been UTF-8 or something else it would have indicated a problem.
When to use the -force_iso, -isoinput and -utf8input indexer options
These options need to be used carefully as they will completely change how PADRE interprets the content:
-
-force_isois to be used when you know that the actual content encoding isISO-8859-1(after having inspected it with n hex editor), and you know that the META tags or HTTP headers are lying. In our case it wouldn’t have helped, because the content is correctly encoded inISO-8859-1, except for those 2 non-breaking space bytes that areUTF-8. PADRE will correctly detect the encoding asISO-8859-1so there’s no need to force it
If a document has no META tags or HTTP headers to give a clue about it’s encoding, PADRE will default to Windows-1252. You can use:
-
-isoinputto force it toISO-8859-1. Note that most people meanWindows-1252when they talk aboutISO-8859-1, so this option is very rarely used. -
-utf8inputto force it to UTF-8
In practice, those options should only be used as workaround if you can’t fix the root cause of the problem, rather than being attempted in the hope of magically fixing the problem.
Index file
It’s interesting to look at the index file, because PADRE will have processed the content and possibly transformed it before storing it on disk. For example, it’s likely that HTML entities will get decoded, so it’s worth checking that they were correctly decoded by PADRE.
You can use the padre-sr utility to inspect the index content:
# You can get the "docnum" 3 by looking at the search results XML or JSON
./bin/padre-sr data/squiz-forum-funnelback/live/idx/index 3 1
# TODO padre-sr broken on search internal :(
# Workaround using padre-di:
./bin/padre-di data/squiz-forum-funnelback/live/idx/index -meta showtopic=12515
Stem = 'data/squiz-forum-funnelback/live/idx/index'
No. docs: 12
[3] forums.squizsuite.net/index.php?showtopic=12515
a: Cromers
c: Funnel back search doesn't allow empty search query - posted in Funnelback: Hi  We have 3 funnelback searches on our site: Business Finder; Course Finder; Job Finder  The first 2 will display all the available results when the page is initially navigated to, however the Job finder only returns result when a query is entered. Is there a setting to fire a blank search that I need to turn on?|Funnel back search doesn't allow empty search query - posted in Funnelback: Hi  We have 3 funnelback searches on our site: Business Finder; Course Finder; Job Finder  The first 2 will display all the available results when the page is initially navigated to, however the Job finder only returns result when a query is entered. Is there a setting to fire a blank search that I need to turn on?
d: 2014-09-22
e: article
s: empty query|search
t: Funnel back search doesn't allow empty search query - Funnelback - Squiz Suite Support Forum
A: Cromers|Aleks Bochniak|Cromers|gordongrace|Cromers|Benjamin Pearson|gordongrace
D: 2014-09-22T09:42:21+00:00|2014-09-22T12:22:33+00:00|2014-09-22T12:43:44+00:00|2014-09-22T13:05:51+00:00|2014-09-22T13:28:39+00:00|2014-09-22T22:57:07+00:00|2014-09-23T08:04:39+00:00
I: http://www.gravatar.com/avatar/e76d223e86038cb76ff3b829ded20999?s=100&d=http%3A%2F%2Fforums.squizsuite.net%2Fpublic%2Fstyle_images%2Fmaster%2Fprofile%2Fdefault_large.png|http://forums.squizsuite.net/uploads/av-1008.jpg?_r=1180422795|http://www.gravatar.com/avatar/e76d223e86038cb76ff3b829ded20999?s=100&d=http%3A%2F%2Fforums.squizsuite.net%2Fpublic%2Fstyle_images%2Fmaster%2Fprofile%2Fdefault_large.png|http://forums.squizsuite.net/uploads/profile/photo-thumb-11031.jpg?_r=1387174259|http://www.gravatar.com/avatar/e76d223e86038cb76ff3b829ded20999?s=100&d=http%3A%2F%2Fforums.squizsuite.net%2Fpublic%2Fstyle_images%2Fmaster%2Fprofile%2Fdefault_large.png|http://forums.squizsuite.net/uploads/av-2430.png?_r=0|http://forums.squizsuite.net/uploads/profile/photo-thumb-11031.jpg?_r=1387174259
S: Hi  We have 3 funnelback searches on our site: Business Finder; Course Finder; Job Finder  The first 2 will display all the available results when the page is initially navigated to, however the Job finder only returns result when a query is entered. Is there a setting to fire a blank search that I need to turn on?|try setting your query parameter to be a null query.  eg. query=!padrenullquery|Hi Aleks  Where do I put this?|Hi Cromers -  Firing a 'blank' or 'null' query is intended to 'show all results'.  Simply showing all results has its own issues, though: How will they be sorted? Date? Title? Size? How will the query summary message be displayed? "You searched for XXX."? What should be logged by the search analytics system? Once you've attempted to answer those questions for yourself, enabling support for null queries is reasonably straightforward.  If you're using the deprecated Classic UI, you can add the following to collection.cfg: ui.null_query_enabled=true| If you're using the Modern UI, two hook scripts will be required:  hook_pre_process.groovy: |// Fix to enable ui.null_query_enabled functionality|if (transaction.question.query == null) {| // query must be set to something or padre isn't called _ is stripped out by padre when processing the query| transaction.question.query = "_"| transaction.question.originalQuery = "_"| // set the system query value to run a null query| transaction.question.additionalParameters["s"] = ["!padrenull"]| }| hook_post_process.groovy: |// Allow the modern UI to handle an undefined queryCleaned value (will occur for the above code as s params aren't included in queryClean)|if ( transaction.response != null && transaction.response.resultPacket.queryCleaned == null)|{| transaction.response.resultPacket.queryCleaned ="";|}| See also: http://docs.funnelba...ok_scripts.html||Hi Gordon  I'm not entirely sure if we are using the Modern UI. We've got Funnelback 13.0 and Matrix 4.14.0.  We already have the search page in place that handles the results with regard to results per page, sort order and filtering. We just want all the results to be returned to the user when they navigate to the search page, in the same way that out other 2 funnelback searched work.|It looks like Funnelback 13.0 does support it... http://docs.funnelba...ok_scripts.html|Hi Cromers -  If you're using Funnelback 13.0, you'll probably be using the Modern UI by default (although support for the Classic UI is still available in that version).  See also: http://docs.funnelba..._interface.html
U: http://forums.squizsuite.net/index.php?s=6258edbbc08a5347636117c80372a804&showtopic=12515#entry54396|http://forums.squizsuite.net/index.php?s=6258edbbc08a5347636117c80372a804&showtopic=12515#entry54397|http://forums.squizsuite.net/index.php?s=6258edbbc08a5347636117c80372a804&showtopic=12515#entry54398|http://forums.squizsuite.net/index.php?s=6258edbbc08a5347636117c80372a804&showtopic=12515#entry54399|http://forums.squizsuite.net/index.php?s=6258edbbc08a5347636117c80372a804&showtopic=12515#entry54400|http://forums.squizsuite.net/index.php?s=6258edbbc08a5347636117c80372a804&showtopic=12515#entry54403|http://forums.squizsuite.net/index.php?s=6258edbbc08a5347636117c80372a804&showtopic=12515#entry54404We can see that:
-
The non-breaking space has indeed been stored as two ISO-8859-1 sequences  and the invisible non-breaking space
-
The apostrophe in the summary is correctly stored. This gives us a clue that the problem with the apostrophe is probably at rendering time rather than crawling / indexing time
If you find a problem at this stage (e.g. the HTML entity for the apostrophe was incorrectly decoded), it’s likely to be a bug in PADRE. It’s unlikely to happen though, because the PADRE code about interpreting content and indexing it is very well exercised and most of the bugs have been ironed out. Usually, when the content is OK, PADRE will index it correctly.
Query processor
Now that we’ve confirmed that the apostrophe is correctly stored on disk, we need to check that the query processor is returning it in correct form when running a query. The first step is to run the query processor on the command line:
./bin/padre-sw data/squiz-forum-funnelback/live/idx/index -res=xml
v:12515
<?xml version="1.0" encoding="UTF-8" standalone="no" ?>
<PADRE_result_packet>
...
<results>
...
<result>
<rank>1</rank>
<score>1000</score>
<title>Funnel back search doesn't allow empty search query - Funnelback - Squiz Suite Support Forum</title>
<collection>squiz-forum-funnelback</collection>
<component>0</component>
<live_url>http://forums.squizsuite.net/index.php?showtopic=12515</live_url>
<summary><![CDATA[Funnel back search doesn't allow empty search query - posted in Funnelback: Hi  We have 3 funnelback searches on our site: Business Finder; Course Finder; Job Finder  The first 2 will display all the available resul
ts when the page is]]></summary>
...We can see that:
-
The apostrophe in the title is represented as
'. While not strictly necessary (an apostrophe is a valid XML character) that’s still a valid way to represent an apostrophe in XML so nothing wrong here -
The apostrophe in the summary is represented as is, but that’s because the summary is enclosed in a CDATA block. In CDATA blocks content is interpreted as is so
'would have stayed'rather than being interpreted as an apostrophe.
User interface layer
When this content is then read by the Modern UI, possibly transformed, and then rendered with FreeMarker to be presented. We need to inspect all of these steps to narrow down the problem.
Note that when inspecting XML and JSON endpoints, your browser will interpret the content to render it in a nice way. It’s preferable to use command line tools like wget or curl to get the raw content, to prevent misleading transformations by the browser.
padre-sw.cgi
First step is to use padre-sw.cgi. The output should be strictly identical as running the query processor on the command line (see
the query processor section above) but that’s a good way to confirm that nothing unexpected happens when PADRE is run by Jetty.
Use the URL /s/padre-sw.cgi:
Validate padre-sw output is the same as using CLI:
curl 'http://search-internal.cbr.au.funnelback.com/s/padre-sw.cgi?collection=squiz-forum-funnelback&query=!nullquery' | less
...
<result>
<rank>3</rank>
<score>553</score>
<title>Funnel back search doesn't allow empty search query - Funnelback - Squiz Suite Support Forum</title>
...
<summary><![CDATA[Funnel back search doesn't allow empty search query - posted in Funnelback: Hi  We have 3 funnelback searches on our site: Business Finder; Course Finder; Job Finder  The first 2 will display all the available results when the page is initiall]]></summary>
...Here we’re getting the exact same output as the command line, so we’re good.
search.xml / search.json
Using the XML or JSON endpoint allows bypassing the FreeMarker rendering to control that the Modern UI is building the right data model.
It’s recommended to use JSON because XML has its own quirks (such as requiring XML entities for special characters) which can be misleading.
# Use python to make the XML more readable
curl 'http://search-internal.cbr.au.funnelback.com/s/search.json?collection=squiz-forum-funnelback&query=!nullquery' | python -m json.tool |less
...
"score": 553,
"summary": "Funnel back search doesn't allow empty search queryHi \u00c2\u00a0 We have 3 funnelback searches on our site: Business Finder; Course Finder; Job Finder \u00c2\u00a0 The first 2 will display all the available results when the page is initiall",
"tags": [],
"tier": 1,
"title": "Funnel back search doesn't allow empty search query"
...-
(Aside: We can confirm that our incorrect non-breaking space is still preserved as C2 A0 in the Modern UI.)
-
We can see that the title apostrophe is preserved alright
-
But we can see that the summary apostrophe has been encoded to
'
That’s normal! The technical details are a bit complex, but the Modern UI will re-encode some special characters from the PADRE result packet: \, ", ', <, > and &.
That’s however where our problem lies. Depending on how the value is interpreted in FreeMarker the encoding will or will not show.
If you encounter a problem at this point it can be either a Modern UI bug or a custom hook script that’s doing something wrong. Try disabling all the hook scripts first.
FreeMarker
Now that we’ve confirmed that the data model is right we need to look at FreeMarker. FreeMarker will take the data model as is and render it to HTML. Different parameters can affect the rendering (The FreeMarker documentation about charsets might be worth reading)
Freemarker <#ftl encoding> directive
This directive is set at the top of the template: <#ftl encoding="utf-8">. It’s used to define in which encoding the .ftl file is stored on disk.
This should not usually be changed because Funnelback writes templates in UTF-8 by default. You need to change that only if you converted the .ftl file to a different encoding for some reason (but there should be no reason to do that).
A global <#escape> directive
Since Funnelback v14 a global escaping directive has been declared at the top of the template: <#escape x as x?html>. It means that all the values from the data model will be automatically escaped to HTML. For example, characters like < will be converted into <.
This is for security reasons, to prevent people from injecting Javascript or HTML. If someone enters a query term like <script>, it will be escaped to <script> and will be correctly displayed as <script> by the browser rather than being interpreted as a script tag.
You need to be aware of this. Since version 14 all variables are HTML encoded by default.
Ad-hoc ?html or ?url statements
Variables can be HTML encoded with ?html or URL encoded with ?url.
-
HTML encoding will convert special characters like
<,>, … into their HTMl entities<,>. That’s used when you want to display content to the user that contains special characters that shouldn’t be interpreted by the browser. For example, if you want to display the literal word<script>you need to write<script>otherwise the browser will interpret it as a<script>HTML tag. -
URL encoding convert special characters in URL to their percent-encoding form. For example a
$will be converted to%24. That’s used when you want to embed special characters in a URL (link, or image source, etc.)
A ad-hoc <#noescape> directive
Sometimes you don’t want the automatic escaping to take place. In that case you need to enclose the variable with a <#noescape> directive.
That’s for example the case with curator or best bets HTML messages. We know that those messages can contain HTML tags like <b>, <i>, … If they were to be automatically escaped, they would end up being displayed a <b> in the results rather than being interpreted as bold.
You’ll note that by default the results summaries are also not escaped:
<@s.boldicize><#noescape>${s.result.summary}</#noescape></@s.boldicize>That’s because the Modern UI is re encoding some special characters as described in the previous section. Let’s take an example:
-
Result summary contains the sentence
5 is > 4 -
Modern UI re-encodes it to
5 is > 4 -
If the variable was escaped, or displayed with
summary?html, it would result in another encoding pass:5 is &gt; 4. The&would be interpreted as&by the browser, and the page would display5 is > 4. -
If the variable was not escaped the data is inserted as is in the HTML source,
5 is > 4. The browser will then interpret>as>, and the page will display:5 is > 4.
In our specific form example that’s where the problem lies. Looking at the form, we can see the summary being displayed as:
Form example:
<p>
<small class="text-muted">
<#if s.result.date??>${s.result.date?date?string("d MMM yyyy")}: </#if>
<#if s.result.metaData["a"]??>${s.result.metaData["a"]} - </#if>
</small>
<@s.boldicize>
${s.result.summary?html}
<!-- ${s.result.metaData["c"]!} -->
</@s.boldicize>
</p>Notice that the summary has a ?html statement in it. Additionally, the global escaping is still in place at the top of the file resulting in a double encoding.
-
Modern UI data model contains
Funnelback doesn't -
The global escape directive at the top of the form encodes it to
Funnelback doesn&#39;t -
The additional
?htmlstatement encodes it toFunnelback doesn&amp;#39;t -
The browser will decode the
&, resulting inFunnelback doesn&#39;tbeing displayed to the user
The correct way to display it should be to bypass all possible encodings:
<#noescape>${s.result.summary}</noescape>HTML output declared encoding
Your FreeMarker template will probably declare an encoding in the HEAD section, something like <meta charset="utf-8">
This cannot be changed to something else. The Modern UI will always output UTF-8 and there’s no way to change that. If you declare a different encoding in your HTML page, the browser will try to interpret the UTF-8 data as a something else, and it will result in corruption.
CMS integration / browser display
The Modern UI can only produce UTF-8. This means that:
-
The web browser should interpret the page as being encoded in
UTF-8. That’s guaranteed by setting the right charset in a META tag -
Any CMS slurping the results should read the content as
UTF-8as well.
Some CMS don’t support rendering UTF-8. There is no possible workaround for that on the Funnelback side. The CMS (or something sitting between the CMS and Funnelback) needs to read the content as UTF-8 and then do its own charsets conversion.
That’s also true for the XML / JSON endpoint. Those endpoint will produce UTF-8 and only UTF-8 so the consumer needs to work with that or do its own conversion.