Implementer training - Index the records in a CSV file
Funnelback provides a built-in filter that converts CSV data into XML that can be indexed by Funnelback.
| The CSVToXML filter also handles a set of related delimited text formats such as tab delimited data. |
Tutorial: Download and index a CSV file
-
Log in to the search dashboard where you are doing your training.
See: Training - search dashboard access information if you’re not sure how to access the training. Ignore this step if you’re treating this as a non-interactive tutorial. -
Create a new search package called Nobel Prize. Skip the step where you are asked about adding data sources.
-
Once the search package is created scroll to Components section and click the create a data source button.
-
Create a data source with the following properties:
-
Data source type:
web -
Data source name:
Nobel Prize winners -
What website do you want to crawl?:
https://docs.squiz.net/training-resources/nobel/nobel.csv -
What filetypes do you want to index?:
csv
-
-
Because we are indexing a CSV file we need to add the CSV to XML filter. Click the edit data source configuration item from the settings panel. Click the add new button and add the filter.classes setting.
-
The filters listed don’t really apply to our search so delete them and replace with the
CSVToXMLfilter. This filter converts CSV into XML, which Funnelback can then index. -
Because our CSV file has a header row you need to also add the following setting: filter.csv-to-xml.has-header and set this to true.
-
Run an update of the data source by clicking the update this data source button.
-
Configure the XML field to metadata class mappings.
Before you add your mappings clear the existing mappings by selecting from the menu. Click the configure metadata mappings item from the settings panel, then add the following metadata class mappings:
Class name Source Type Search behaviour year/csvFields/Yeartext
searchable as content
category/csvFields/Categorytext
searchable as content
name/csvFields/Nametext
searchable as content
birthDate/csvFields/Birthdatetext
display only
birthPlace/csvFields/Birth_Placetext
searchable as content
country/csvFields/Countrytext
searchable as content
residence/csvFields/Residencetext
searchable as content
roleAffiliate/csvFields/Role_Affiliatetext
searchable as content
fieldLanguage/csvFields/Field_Languagetext
searchable as content
prizeName/csvFields/Prize_Nametext
searchable as content
motivation/csvFields/Motivationtext
searchable as content
-
Apply the metadata to the index by running an advanced update to rebuild the live index.
-
Return to the search package and add a results page named Nobel Prize winners search
-
Edit the default template to return metadata for each search result. Replace the contents of the
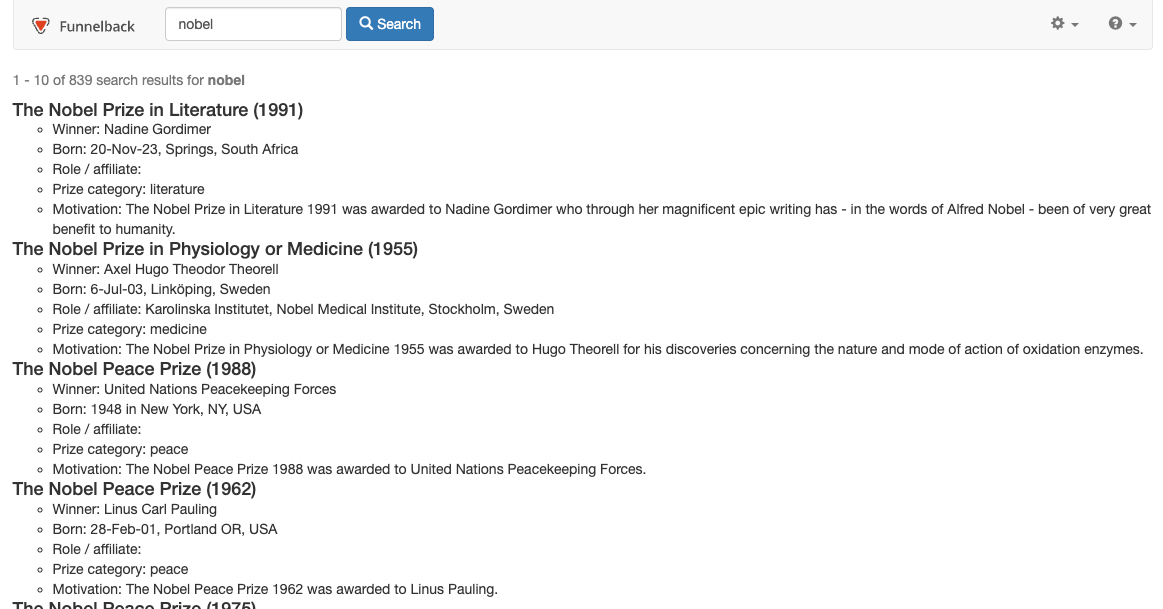
<@s.Results>tag with the following then save and publish the template:<@s.Results> <#if s.result.class.simpleName != "TierBar"> <li data-fb-result=${s.result.indexUrl}> <h4>${s.result.listMetadata["prizeName"]?first!} (${s.result.listMetadata["year"]?first!})</h4> <ul> <li>Winner: ${s.result.listMetadata["name"]?first!}</li> <li>Born: ${s.result.listMetadata["birthDate"]?first!}, ${s.result.listMetadata["birthPlace"]?first!}, ${s.result.listMetadata["country"]?first!}</li> <li>Role / affiliate: ${s.result.listMetadata["roleAffiliate"]?first!}</li> <li>Prize category: ${s.result.listMetadata["category"]?first!}</li> <li>Motivation: ${s.result.listMetadata["motivation"]?first!}</li> </ul> </li> </#if> </@s.Results> -
Configure the display options so that relevant metadata is returned with the search results. Click the edit results page configuration item from the customize panel then add the following to the query_processor_options setting:
-SF=[year,category,name,birthDate,birthPlace,country,residence,roleAffiliate,fieldLanguage,prizeName,motivation] -
Run a search for nobel to confirm that the CSV has been indexed as individual records and that the metadata is correctly returned.