Transform or analyze content before it is indexed
| Before you start check to see if there is an existing built-in filter or plugin that provides the functionality that you require. |
Funnelback’s data source update flow provides a filter phase which provides the ability to transform or analyze document content prior to it being stored for indexing.
Filtering is the process of transforming or analyzing gathered content into content suitable for indexing by Funnelback.
This can cover a number of different scenarios including:
-
File format conversion - converting binary file formats such as PDF and Word documents into text suitable for indexing.
-
Text mining and entity extraction
-
Document geocoding
-
Metadata generation
-
Content and WCAG checking
-
Content cleaning
How does this work?
Filtering passes the raw document through multiple chained filters each of which may modify the document. These modifications may include converting the document from a binary format such as PDF to an indexable text format or modifying the document by adding metadata or altering the document’s URL.
Filtering is run during the gather phase of a data source update and occurs after the document is downloaded from the content source but before it is stored on disk. For the push data sources, the filter.classes provided in the data source configuration will be applied. This will be overridden if the filter parameter is set when API is called.
| A full update is required after making any changes to filters as documents that are copied during an incremental update are not re-filtered. Full updates are started from the data source advanced update screen. |
Generic document and HTML document (jsoup) filters
Funnelback supports two main types of filters:
-
Generic document filters operate on the document as a whole taking the complete document as an input, applying some sort of transformation then outputting complete document which can then be fed into another filter. A generic document filter treats the document as either a binary byte stream, or as an unstructured blob of text.
-
HTML document filters (jsoup filters) are special filters that apply only to HTML documents. A HTML document filter handles the HTML as a structured object allowing precise and complex manipulation of the HTML document. HTML document (jsoup) filters are only run when the
JSoupProcessingFilterProvideris included in the filter chain.
The filter chain
The filter chain specifies the set of generic document filters that will be applied to a document after it is gathered prior to indexing. The contents of the gathered document passes through each filter in turn with the modified output being passed on to the input of next filter.
A typical filter chain is shown below. A binary document is converted to text using the Tika filters. This extracts the document text and outputs the document as HTML. This HTML is then passed through the JSoup filter (see the HTML document filters section below) which enables targeted modification of the HTML content and structure. Finally a custom filter performs a number of modifications to the content.

Each filter is represented by a Java class name, with filters separated by either a comma or semi-colon to denote a choice or chain (see below).
The filters that make up the chain are chosen from:
-
Built-in filters: filters that are part of the core Funnelback product.
-
Plugins: filters that are provided by enabling specific Funnelback plugins.
-
Custom Groovy filters: (Deprecated) User-defined Groovy filters that implement custom filter logic. (Not available in the Squiz DXP)
Filter chain steps
The filter chain is made up of a series of chained filtering steps which are executed in order with the output of the first step in the chain being fed into the second step in the chain.
Each step in the chain must specify one or more filters. If more than one filter is specified then a choice is made between the specified filters and up to one of these filters will be run.
| It is possible that none of the filters will match execution rules in which case the document content is passed through unchanged to the next filter in the chain. |
For the filter chain represented graphically below:
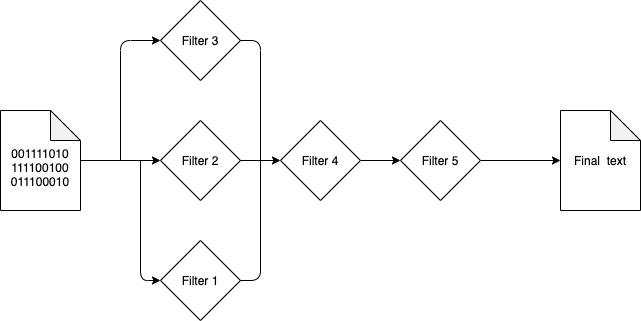
The binary input content would pass through either Filter3, Filter2, Filter1 or none of these (in that order) before passing through Filter4 and Filter5.
|
Designing a custom filter
When designing a custom filter consider carefully the function that the filter performs. Limit the implementation to reusable chunks of functionality that can be chained together, each developed as a separate filter.
When writing a new custom filter you should consider the following:
-
What type of content will the filter be transforming or analyzing?
When considering this question think about the input that the filter will receive - for example most binary documents will be converted to text by the Tika filter which is the first filter to run. The output of this filter is text and any filters that operate on documents that have been filtered by Tika will receive text (not binary) content as the input. -
html document content only: create a HTML document (jsoup) filter. This is used when you want to manipulate or analyze a html document, using a Jsoup document object
if you are writing a filter that needs to process HTML and XML document content, or just want to work on the document text instead of a structured object then consider the text document content case below. -
text document content: create a document filter that implements the
StringDocumentFilterinterface. -
binary document content: create a document filter that implements the
BytesDocumentFilterinterface. This is used by the Tika filter that converts binary documents into indexable text. -
the filter won’t be analyzing or processing the document content: create a filter that implements the generic
Filterinterface. This is used for filters that must run on documents but don’t need access to the content of the document. For example a filter that only adds metadata to a document which is independent of the content, or a filter that removes documents based on the URL.
-
-
Should your filter only run under certain conditions? For example, only run if the source document is of a particular MIME type or has a particular file extension. See: pre-filter checks.
Convert a Groovy custom filter into a filter plugin
The basic process is as follows:
-
Inspect the existing filter and make a note of the filter’s package name (from the
packageline at the top of the file) and class name (from thepublic class CLASS-NAME implements FILTER-INTERFACEline) -
Create a new plugin using the plugin Archetype.
-
When prompted, set the
groupIdto the existing plugin’s package name. -
When prompted, set the
artifactIdto the existing plugin’s class name. -
When prompted, set the
packageto the existing plugin’spackage.artifactId -
Provide appropriate values for the
plugin-name,plugin-description -
When prompted, set
runs-on-datasourcetotrue -
When prompted, set
runs-on-results-pagetofalse -
When prompted for plugin templates, include at a minimum
-
filtering: if you are converting a document filter. -
jsoup-filtering: if you are converting a HTML document (jsoup) filter.
-
If your filter adds metadata that you have to manually map as part of the setup you should include the indexinginterface which allows you to auto-configure metadata mappings that are set up when the plugin is enabled. -
-
Copy the Groovy filter code into the corresponding java file that is created as part of your new plugin.
-
Convert any Groovy code into Java and fix any errors and missing imports.
-
Write appropriate tests.
-
Test and submit the plugin for review.