Implementer training - Data source update cycle
When you start an update, Funnelback commences on a journey that consists of a number of processes or phases.
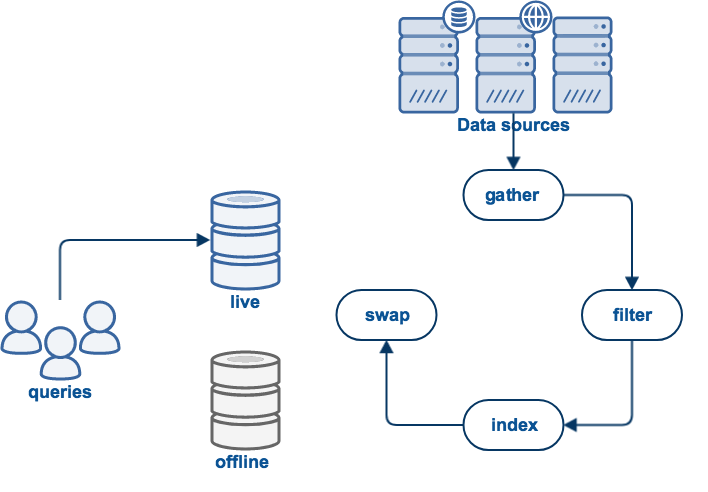
Each of these phases must be completed for a successful update to occur. If something goes wrong an error will be raised and this will result in a failed update.
The exact set of phases will depend on what type of data source is being updated - however all data source generally have the following phases:
-
A gather phase that is the process of Funnelback accessing and storing the source data.
-
A filter phase that transforms the stored data.
-
An index phase that results in a searchable index of the data.
-
A swap phase that makes the updated search live.
Gathering
The gather phase covers the set of processes involved in retrieving the content from the data source.
The gather process needs to implement any logic required to connect to the data source and fetch the content.
The overall scope of what to gather also needs to be considered.
For a web data source the process of gathering is performed by a web crawler. The web crawler works by accessing a seed URL (or set of URLs). The seed (or start) URLs are the same as the URL(s) you entered in the What website(s) do you want to crawl? step when creating the data source.
The seed URLs are always fetched by the web crawler and stored locally. The crawler then parses the downloaded HTML content and extracts all the links contained within the file. These links are added to a list of URLs (known as the crawl frontier) that the crawler needs to process.
Each URL in the frontier is processed in turn. The crawler needs to decide if this URL should be included in the search - this includes checking a set of include / exclude patterns, robots.txt rules, file type and other attributes about the page. If all the checks are passed the crawler fetches the URL and stores the document locally. Links contained within the HTML are extracted and the process continues until the crawl frontier is empty, or a pre-determined timeout is reached.
The logic implemented by the web crawler includes a lot of additional features designed to optimize the crawl. On subsequent updates this includes the ability to decide if a URL has changed since the last visit by the crawler.
Crawler limitations
The web crawler has some limitations that are important to understand:
-
The web crawler does not process JavaScript. Any content that can’t be accessed when JavaScript is disabled will be hidden from the web crawler.
-
It is possible to crawl some authenticated websites, however this happens as a specified user. If content is personalized, then what is included in the index is what the crawler’s user can see.
-
By default, the crawler will skip documents that are larger than 10MB in size (this value can be adjusted).
Filtering
Filtering is the process of transforming the downloaded content into text suitable for indexing by Funnelback.
This can cover a number of different scenarios including:
-
file format conversion - converting binary file formats such as PDF and Word documents into text.
-
text mining and entity extraction
-
document geocoding
-
metadata generation
-
content and WCAG checking
-
content cleaning
-
additional or custom transformations defined in a filter plugin.
Indexing
The indexing phase creates a searchable index from the set of filtered documents downloaded by Funnelback.
The main search index is made up of an index of all words found in the filtered content and where the words occur. Additional indexes are built containing other data pertaining to the documents. These indexes include document metadata, link information, auto-completion and other document attributes (such as the modified date and file size and type).
Once the index is built it can be queried and does not require the source data used to produce the search results.
Swap views
The swap views phase serves two functions - it provides a sanity check on the index size and performs the operation of making the updated indexes live.
All Funnelback data sources (except push data sources) maintain two copies of the search index known as the live view and the offline view.
When the update is run all processes operate on an offline view of the data source. This offline view is used to store all the content from the new update and build the indexes. Once the indexes are built they are compared to what is currently in the live view - the set of indexes that are currently in a live state and available for querying.
The index sizes are compared. If Funnelback finds that the index has shrunk in size below a definable value (for example, 50%) then the update will fail. This sanity check means that an update won’t succeed if the website was unavailable for a significant duration of the crawl.
An administrator can override this if the size reduction is expected. For example, a new site has been launched, and it’s a fraction of the size of the old site.
Push data sources used an API based mechanism to update and will be covered separately.