Implementer training - Checking an update
Funnelback maintains detailed logs for all processes that run during an update.
When there is a problem and an update fails the logs should contain information that allows the cause to be determined.
It is good practice to also check the log files while performing the setup of a new data source - some errors don’t cause an update to fail. A bit of log analysis while building a data source can allow you to identify:
-
pages that should be excluded from the crawl
-
crawler traps
-
documents that are too large
-
documents of other types
Each of the phases above generate their own log files - learning what these are and what to look out for will help you to solve problems much more quickly.
|
The information in the
|
Tutorial: Examine update logs
In this exercise some of the most useful log files generated during an update of a web data source will be examined.
-
Log in to the search dashboard where you are doing your training.
See: Training - search dashboard access information if you’re not sure how to access the training. Ignore this step if you’re treating this as a non-interactive tutorial. -
Locate the austen data source that you created in the previous exercise.
-
Open the manage data source screen (by clicking on the funnelback website title, or selecting the > configuration menu item. The status should now be showing update complete, which indicates that the update completed successfully.

-
View the log files for the update by clicking on the browse log files link in the tools section.
-
Observe the log manager view of the available log files. The files are grouped under several headings including: collection log files, offline log files and live log files.
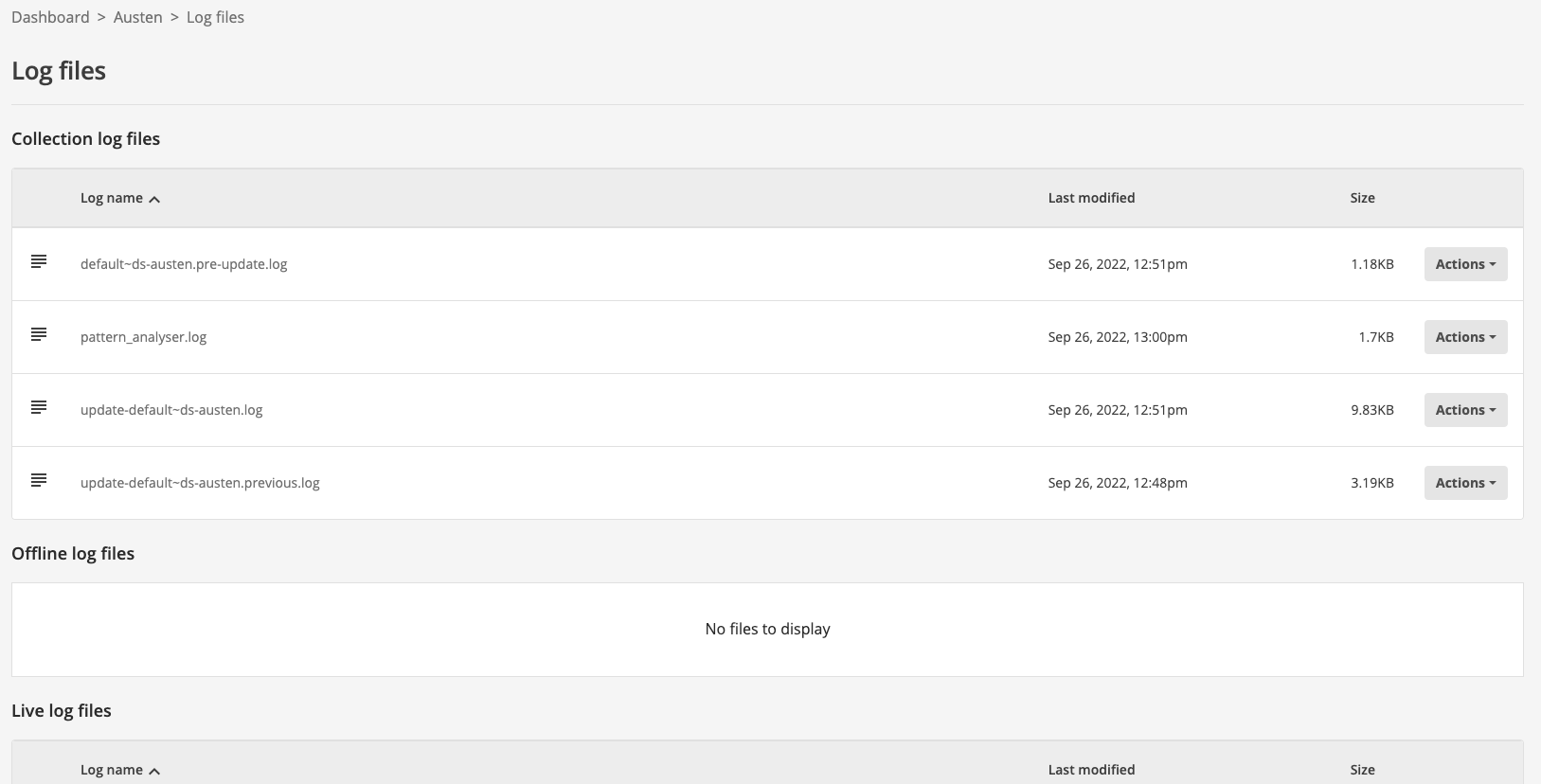
The collection log files section contains the top-level update and report logs for the data source. The top-level update log contains high-level information relating to the data source update.
The live log files section includes all the detailed logs for the currently live view of the search. This is where you will find logs for the last successful update.
The offline log files section includes detailed logs for the offline view of the search. The state of the log files will depend on the data source’s state - it will contain one of the following:
-
Detailed logs for an update that is currently in progress
-
Detailed logs for the previous update (that failed)
-
Detailed logs for the successful update that occurred prior to the currently live update.
-
Debugging failed updates
An update can fail for numerous reasons. The following provides some high level guidance by providing some common failures and how to debug them.
The first step is to check the data source’s update log and see where and why the update failed. Look for error lines. Common errors include:
-
No documents stored: For some reason Funnelback was unable to access any documents so the whole update failed (as there is nothing to crawl). Look at the offline crawl logs (
crawler.log,crawl.log.X.gz) andurl_errors.logfor more information. The failure could be the result of a timeout, or a password expiring if you are crawling with authentication. -
Failed changeover conditions: After building the index a check is done comparing with the previous index. If the index shrinks below a threshold then the update will fail. This can occur if one of the sites was down when the crawl occurred, or if there were excessive timeouts, or if the site has shrunk (for example, because it has been redeveloped or part of it archived). If a shrink in size is expected you can run an advanced update and swap the views.
-
Failures during filtering: Occasionally the filtering process crashes causing an update to fail. The
crawl.logorgather.logmay provide further information to the cause. -
Lock file exists: The update could not start because a lock file was preventing the update. This could be because another update on the collection was running; or a previous update crashed leaving the lock files in place. The lock can be cleared from the search dashboard by selecting the collection then clicking on the clear locks link that should be showing on the update tab.
-
Failures during indexing: Have a look at the offline index logs (
Step-*.log) for more details.
Tutorial: Debug a failed update
In this exercise we will update the configuration so that the crawler is unable to access the start URL to provide a simple example of debugging an update.
-
Log in to the search dashboard where you are doing your training.
See: Training - search dashboard access information if you’re not sure how to access the training. Ignore this step if you’re treating this as a non-interactive tutorial. -
locate the austen data source.
-
Open the manage data source screen (by clicking on the austen title, or selecting the > configuration menu item. The status should now be showing update complete, which indicates that the update completed successfully.
-
Access the data source configuration by clicking the edit data source configuration option in the settings section.
-
Update the start url by clicking on the
start_urlitem. Update the value tohttps://docs.squiz.net/training-resources/austin/(changeaustentoaustin) then save your changes. We are intentionally using a URL containing a typo in this example so we can examine the resulting errors.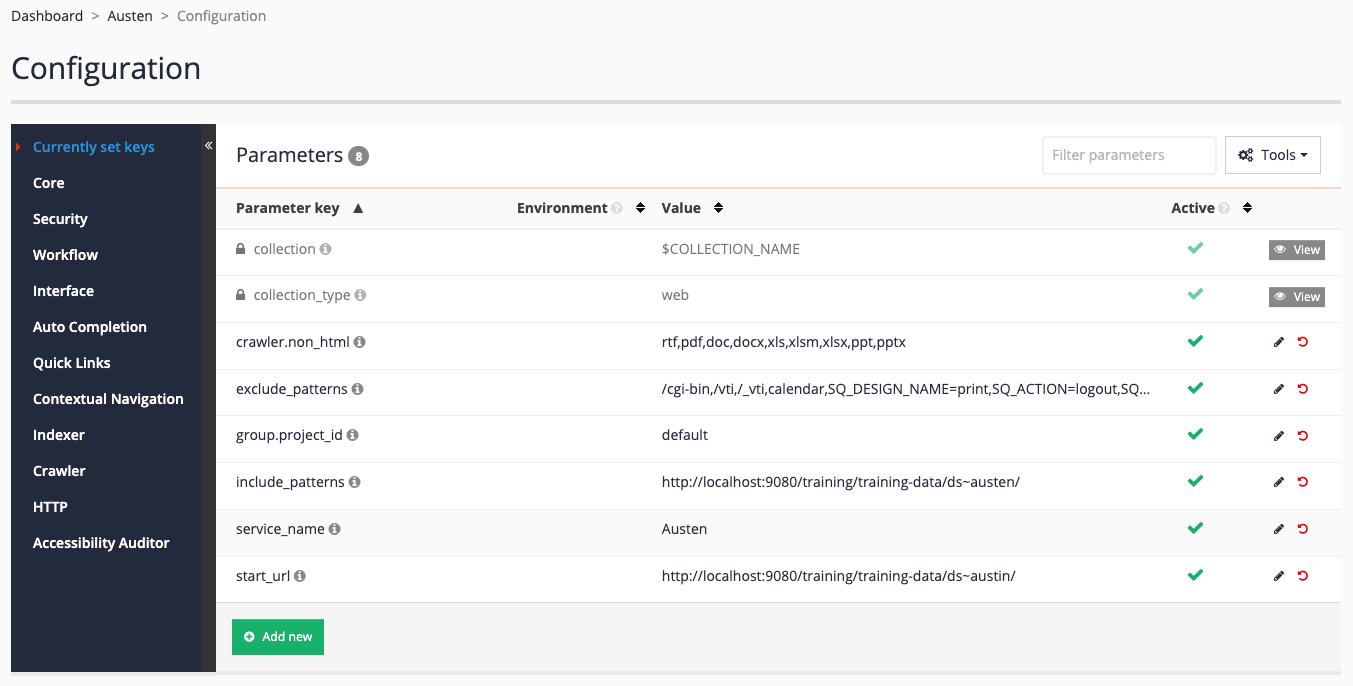
-
Return to the data source manage screen by clicking Austen in the breadcrumbs, then start an update by clicking on the update data source item in the update section. The update should fail almost immediately, and the status will update to show update failed (note you might need to refresh your browser screen).
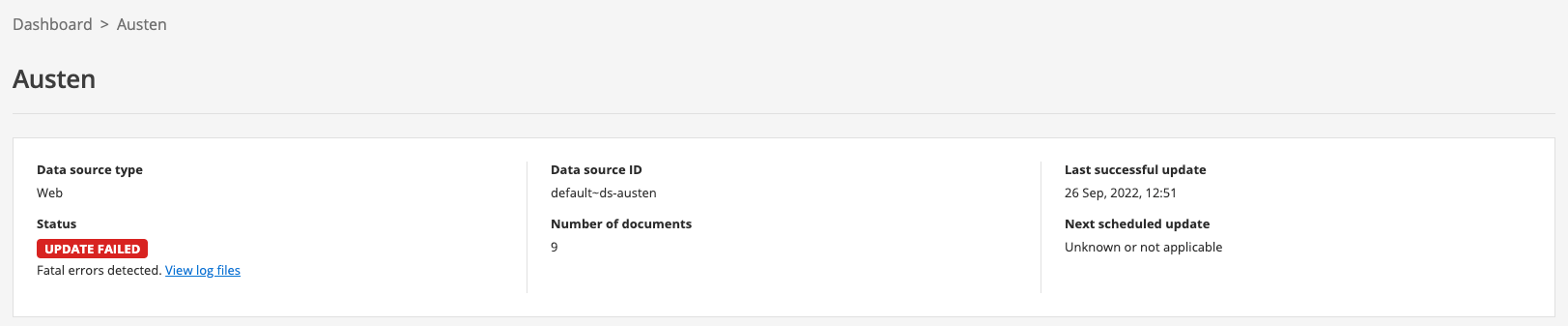
-
Access the logs (click on browse log files in the tools section). Inspect the log files for the data source - starting with the
update-training~ds-austen.log. Theupdate-<DATA-SOURCE-ID>.logprovides an overview of the update process and should give you an idea of where the update failed. Observe that there is an error returned by the crawl step. This suggests that we should investigate the crawl logs further.
-
As the data source update failed, the offline view will contain all the log files for the update that failed. Locate the
crawler.logfrom the offline logs section and inspect this. The log reports that no URLs were stored.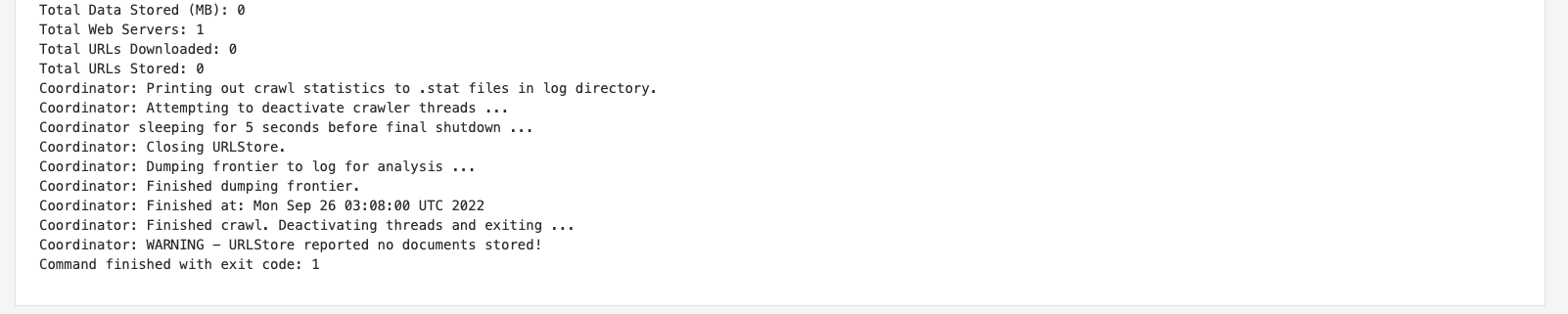
-
Examine the
url_errors.logwhich logs errors that occurred during the crawl. From this log you can see that a 404 not found error was returned when accessinghttp://localhost:9080/training/training-data/ds~austin/which is the seed URL for the crawl. This explains why nothing was indexed because the start page was not found, so the crawl could not progress any further.E https://docs.squiz.net/training-resources/austin/ [404 Not Found] [2022:09:26:03:07:54] -
With this information at hand you can investigate further. In this case the reason the crawl failed was due to the seed URL being incorrectly typed. But you might visit the seed URL from your browser to investigate further.
-
Return to the edit data source configuration screen and correct the start URL.
Review questions: debugging failed updates
-
What’s the difference between the live and offline logs and when would you look at logs from each of these log folders?
-
Which logs would you look at to solve the following?
-
Find files that were rejected due to size during the last update?
-
Find the cause of an update that failed?
-
Determine why a URL is missing from an index?
-
Identify unwanted items that are being stored?
-