Library of available plugins and filters
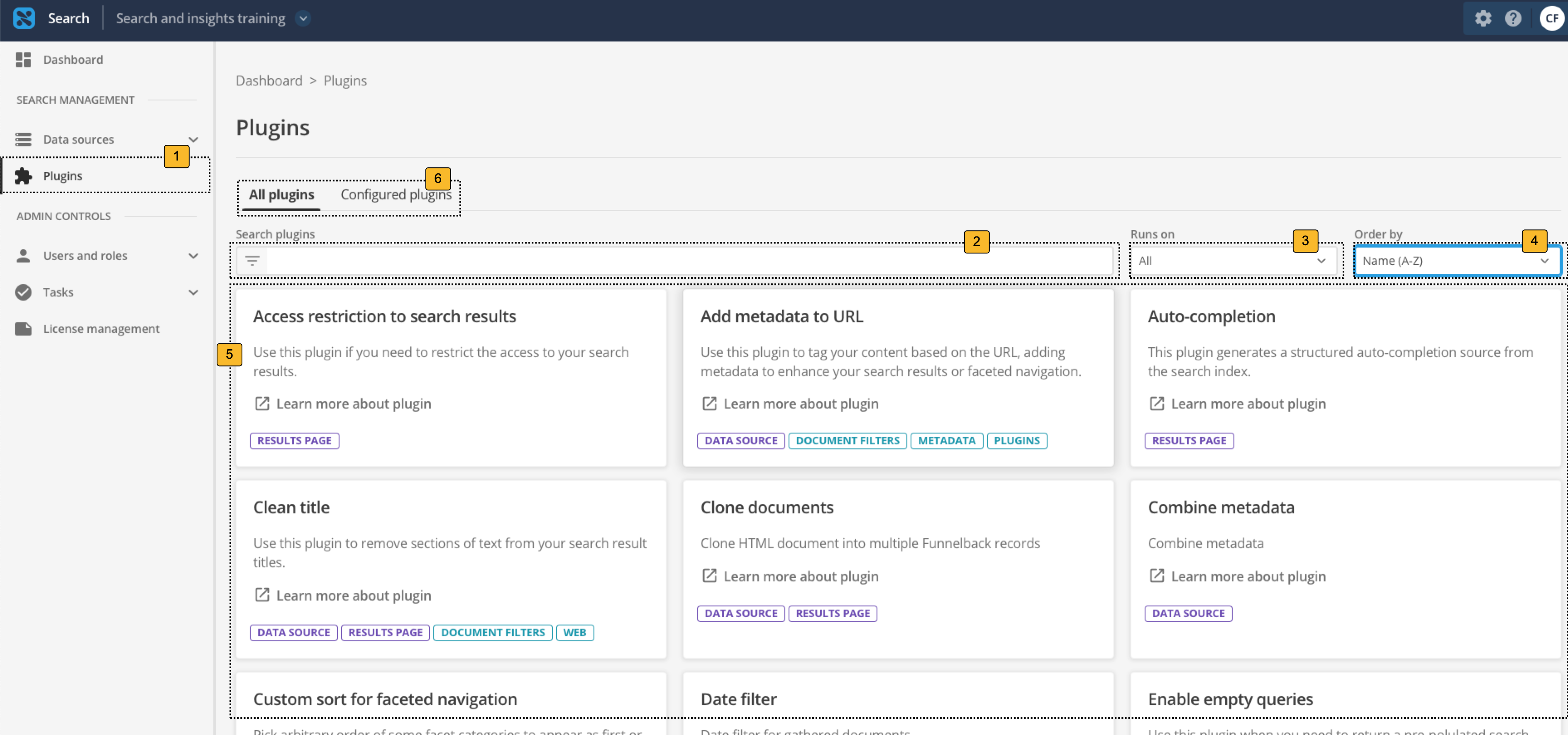
Available plugins are listed on the plugins screen, which can be accessed from the navigation panel within the search dashboard.
-
Clicking the plugins item opens the plugin management screen (the screen pictured above).
-
Entering keywords into this box will filter the plugins displayed in the main panel 5
-
Filter the plugins in the main panel to only list plugins for data sources or results pages.
-
Define how the plugins are sorted in the table. Options are by popularity (based on how often the plugin is enabled on this server) or alphabetically (A-Z or Z-A) based on the plugin’s title.
-
The main panel lists the plugins available to use in your search, filtered and sorted 2-4. Clicking on a plugin tile opens a screen allowing you to enable the plugin on your search.
-
Use the tabs to switch between a listing showing all available plugins, and a listing of results pages and data sources that are using plugins.
For information on built-in filters, please see the filters section.
Available plugins and filters
| This table includes plugins and built-in filters. To use a built-in filter please see the notes within the documentation page for the relevant filter. Filters are included here because they provide similar plugin-style functionality, but these are not configured via the plugin management screens.. |
The following plugins and filters are available for use:
| Plugin or filter | Description |
|---|---|
Use this plugin to index a set of programs/courses from the Modern Campus Acalog API. |
|
Use this plugin if you need to restrict the access to your search results. |
|
Use this plugin to tag your content based on the URL, adding metadata to enhance your search results or faceted navigation. |
|
Use this plugin if you need to update the URL that is associated with a search result. |
|
Use this plugin to generate structured auto-completion from your search index. |
|
Use this plugin to remove non-printable or control characters from downloaded text content. |
|
Use this plugin to remove sections of text from your search result titles. |
|
Use this plugin when you need to return a HTML document multiple times in the search results. |
|
Use this plugin if you need to combine several metadata fields into a new metadata field, or to clone an existing metadata field. |
|
Use this plugin if you need to exclude documents in an XML or HTML data source based on a date/time contained in the document itself. |
|
Use this plugin to restrict your search results to items with past or future dates. |
|
Use this plugin to exclude a document based on the content within the document. Datasource update expects at least one document to be found, therefore if all documents are filtered out the update will fail. |
|
Use this plugin to download external metadata configuration from one or more publicly accessible URLs during an update. |
|
Use this plugin when you want to display extra search results only when a specific tab is selected. |
|
Use this plugin when you are displaying an extra search that shows a few results from another tab, and you wish to provide a link with the extra search that allows you to view all the results. |
|
Use this plugin to control the order that facets are returned in the data model. |
|
Use this plugin if you need to date sort facet categories that have a custom date format. |
|
Use this plugin if you need to define a custom sort order for the categories listed beneath a facet. |
|
Set the facet default category selection based on other facet selections. |
|
Use this plugin to download document kill and query independent evidence (QIE) configuration from one or more publicly accessible URLs during an update. |
|
This plugin forces all downloaded documents to be processed as XML. |
|
Use this plugin to generate a list of start URLs for a paginated API, where the total number of pages is read from an API response. |
|
Use this plugin to include content from Google Calendar in your search results. |
|
Use this plugin if you need to group your search results by data source or a metadata field. |
|
Use this plugin if you need to curate the file type names that are recorded for documents, if presenting file type information in facets or result summaries. |
|
Use this plugin to include Instagram content in your search results. |
|
Use this plugin when migrating a search that relies on legacy stencils into the DXP. |
|
Use this plugin if you need to support non-standard query parameters when calling the search. |
|
Use this plugin when you need to define metadata field specific delimiters for the splitting of the metadata fields values. |
|
Use this plugin to index microdata and JSON-LD as metadata. |
|
Use this plugin to update or set fields in the extra search request. |
|
Use this plugin to modify and transform JSON data that has been downloaded before indexing. |
|
Use this plugin to when you wish to customize your pagination control in the search results. |
|
Use this plugin when you need to return a pre-polulated search results page, or set a default query to run when the user submits an empty query. |
|
Use this plugin when you need to support wildcards (e.g. pic*) in your search. |
|
The purpose of this plugin is to provide the search administrator with a way of controlling what populates the result title. |
|
Use this plugin if you need to change the value of any facet category labels. |
|
Use this plugin if you are relying on some legacy faceted navigation data model fields which were removed in v16, and can’t easily update your integration. |
|
Use this plugin when you need to download and index content from an SFTP server. |
|
Use this plugin if you want to be able to search for user mentions ( |
|
Use this plugin if you have XML or HTML documents that you wish to split and index as separate search result items. Splits HTML and XML documents based on X-Path or CSS selector patterns. |
|
Use this plugin if you need to strip HTML markup tags from XML document content. |
|
Use this plugin when you need to display a tab facet nested inside another tab facet. |
|
Use this plugin if you need to remove parameters such as sort and num_ranks when navigating between tabs. |
|
Use this plugin when you are using tab facets and need to specify a default tab to select. |
|
Use this plugin to transform the value of date fields. |
|
Use this plugin if you need to apply a transformation to XML data before indexing. |
|
Use this plugin to index content from a paid Twitter service using the V2 API. |
|
Store documents in S3 bucket for vector chunking |
|
Use this plugin to index public content from the Vimeo video platform. |
|
This plugin is used to scan files against viruses before uploading into Funnelback using the DXP virus scanning API. |
|
Use this plugin if you are detecting incorrect forwarding IP addresses in your analytics or IP restrictions. This plugin can be used to remove some IP addresses from the |
|
Excludes documents in an XML data source based on a date/time contained in the XML data. |
|
Use this plugin when you need to index an XML field containing HTML as a HTML inner document, and it isn’t correctly detected as HTML. |
|
Use this built-in filter to convert records in a CSV, TSV, SQL or Excel document into multiple XML documents. |
|
Use this built-in filter to convert JSON documents into XML. |
|
Use this built-in filter to replace poor HTML document titles. The filter analyzes the document title and attempts to replace it if the title is not considered a good title. HTML documents only. |
|
(deprecated) Use this built-in filter to convert documents using an external converter program. |
|
Use this built-in filter to force all documents to be processed with an assigned |
|
Use this built-in filter to force all documents to be processed with an assigned |
|
Deprecated. Use the Force XML plugin. Do not use. Previously this built-in filter was used to force all documents to be processed with an assigned |
|
Use this built-in filter to force all documents to be processed with an assigned |
|
Use this built-in filter to remove headers/footers and navigation from your search results by automatically inserting noindex tags into HTML documents based on CSS selectors. |
|
Use this built-in filter to enable the transformation of HTML documents using a set of Jsoup filters that operate on the HTML document structure. |
|
Use this built-in filter to add additional metadata, extracted from HTML and XML document content. |
|
Use this built-in filter to clean, transform and normalize metadata values. |
|
Use this built-in filter to convert binary files of specific file formats (Microsoft Office files, PDF files, etc.) into HTML using Apache Tika. |
|
Use this built-in filter to detect if a URL contains textual content. Used by the Content Auditor. |
|
(deprecated) Used for generic filtering workflows (for example, inserting metadata based on URL patterns, performing string replacements, etc.) |
|
Use this filter to detect the content generator for a HTML page. |
|
Use this filter to analyze the reading grade level of a HTML page. |
|
Use this filter to analyze HTML page content for undesirable text. |
|
Use this filter to detect HTML pages containing duplicate titles. |