Learn about the Funnelback ranking algorithm
More effective search delivers considerable value to searchers, by finding information and services which would otherwise remain hidden or by saving time. An ideal search engine would find all useful information and services within the domain being searched, return them to the searcher in order of decreasing value to the searcher (taking into account overlap with what has already been presented earlier in the list) and present each result in a way which facilitates assessment of its value.
This document describes how out-of-the-box Funnelback ranks documents, explains how to modify settings to meet particular needs and links to documentation on monitoring and measuring effectiveness of search at your site.
Funnelback, like other leading search engines, is based on statistical algorithms and "understands" neither the query nor the content of documents. Accordingly, evaluation of the quality of search should be based on a large number (50+) of queries.
Initial ranking
If you are not yet familiar with Funnelback’s query language, please refer to the user help pages on the query language.
Funnelback assigns each document a utility score derived from the factors listed below and records how many of the constraints implicit in the query (in simple queries, each query word counts as a constraint) it satisfied. Results are then sorted into 'tiers' by decreasing number of constraints matched. Results within these 'tiers' are by default listed in decreasing order by score but may be modified to be ranked on numerous other bases (for example, alphabetical order, date, etc…)
Document content
The particular relevance formula used is a slightly modified form of the Okapi BM25 function developed by Steve Robertson and Steve Walker of City University, London. BM25 embodies the following heuristics:
-
The more occurrences of a query word in a document the better.
-
Shorter documents are preferred to long ones.
-
Query words which occur in fewer documents (lower document frequency) are more discriminating and receive higher weight.
By default, document content includes text plus title and subject, keywords or description metadata. In document content scoring, each word occurrence counts equally, whether in the body of the document or in the title or in metadata, and the document frequency is a count of all documents which contain at least one occurrence in any of these places.
Document metadata
The Okapi BM25 formula is also used for scoring metadata. Metadata explicitly comes into play when a query term includes a metadata field specification but also implicitly when a simple query term is processed. For example, if the query were library, a document content score would be calculated as described in the previous item, but it would be augmented by the scores for occurrences of the query word in the title of the document (i.e. it would be as if the query term t:library was added to the query). Note that this process may result in substantial score boosts to documents containing library in their title due to lower document frequency. (i.e. there may be thousands of documents containing library but probably only a few contain the word in their title) It is possible to configure Funnelback to specify a different set of implicit metadata fields (see below.) The implicit metadata terms included in each query by default are:
-
Title metadata (metadata class t): Words that occur in the 'title' section of each document
-
Incoming anchor text (metadata class k): Funnelback collects together all the anchor text (the words you click on in your browser in order to follow a link) and associates them with the target document as k: metadata. In a web site, anchor text can provide a very strong signal that a certain page is the best answer to a particular query. For example, thousands of pages may contain the word library but probably only a very small percentage contain the word in their k: metadata. Of the pages which do, the k: metadata for the main library home page may contain hundreds more occurrences than any other page. Anchor text scoring uses a different function which removes the length heuristic and increases the weight given to documents with very large numbers of occurrences of query words in the incoming anchor text.
-
Click data (metadata class K): Funnelback can be set up to take into account the number of times users have clicked on a particular resource when using Funnelback search. Every click counts as an occurrence of the search terms used in the k: metadata class. Using click data can improve search results by leveraging the users ability to discern what are and aren’t important results. This means that results that are clicked on more will be boosted in the rankings.
Onsite and offsite inlink count
Anchor text provides strong query-dependent evidence that some pages are more important than others which also match the query. Sometimes it is useful to take into account query-independent evidence. This might be the case if the site used poor anchor text (for example, "click here") or if the query did not use the same language as the anchor text (for example, the query were books rather than library.) Funnelback counts up the number of incoming links and interprets them as votes that this page is useful. The count distinguishes links from the same site and those from outside and weights them differently.
URL length
Generally, important pages (particularly site home pages) have shorter URLs. Funnelback derives a score based on URL length - the shorter the URL the higher the score.
Query independent evidence (QIE)
Evidence can be used that ranks a site’s importance regardless of the query that has been issued. This is useful for manually boosting the rankings of important sites or pages. Careless use of this can significantly harm result quality though. More information is available in a separate document on query independent evidence.
Recency
Recent information may be more valuable than old. For example, people may prefer to read the 2003 annual report than the one for 2002. Furthermore, link-based measures such as anchor text and in-link counts are biased against new pages because it takes time for web authors to notice new pages and link to them.
Document matching
Funnelback supports two document matching approaches:
-
Document at a time (DAAT), the default. The posting lists for all query terms (which are sorted by decreasing significance) are traversed in parallel until there are sufficient candidates for the result list. Thus queries complete faster and minimizes memory use.
-
Term at a Time (TAAT). The complete postings list for each query term are successively scanned to build up a list of candidate results. For large indexes this can result in high memory usage since the candidate result list can grow very large.
The bigger picture
There are more than 70 tunable parameters in the Funnelback ranking algorithm. Out-of-the-box, more than a dozen of these have non-zero values.
We strongly recommend the use of our tuning system, made accessible and easy-to-use via our administrator interface to achieve the best combination of settings for your data and your users. Manual configuration of the system is possible but often achieves poor results because a human tends to focus on too few test queries and too few of the ranking parameters. A massive change in the weight for a parameter may fix a ranking issue for one query but at the same time harm the ranking of a hundred others. In contrast, if our automated tuner is given a representative set of 100 query-best-answers combinations, it can systematically explore the space of possible parameter settings and optimise performance over the whole workload of the search installation.
Re-sorting the result list
Once the initial ranking has been derived as described above, results may be re-sorted if requested by either a -sort query processor option or a sort CGI parameter. This re-sorting can be performed in ascending or descending order by:
-
Recency of the document (Note not all documents have date information included in them so use this option with care)
-
Title of the document
-
Size of the document (In bytes)
-
URL of the document
-
Collection that the document has come from
-
By a specified metadata class.
In each of these cases the score of the document is used to break ties.
Sorting may be performed on top ranking documents (i.e. Those documents that are in the top 'tier') or performed for every 'tier' of results, using the -sortall query processor option. (Note that resorting will not move documents between 'tiers')
When sorting non-English strings in titles, URLs or metadata, you will need to specify the collation order which should apply. This is done by specifying the query processor option -lang= or the corresponding CGI parameter. For example -lang=jp or -lang=jp_JP to achieve sorting appropriate for Japanese. Collation orders and other language specifics are usually defined by the host operating system as 'locales'. To achieve correct sorting for a language the system administrator for the Funnelback servers may need to install a language pack for the operating system.
Collation rules for different languages are quite different. For example, in Czech (locale cs_CZ) accented versions of letters are grouped after the unaccented letter, and the 'ch' combination comes between h and i in the collation order.
Result set diversification
Same site suppression Same site suppression can be used (with the -SSS query processor option) where explicit resorting is not specified. In cases where a number of sites contribute results for a query, it is undesirable that the result ranking be flooded with results from a single source. Funnelback addresses this problem by down weighting additional results from the same site. Using the default settings the second result from a site receives 70% of its raw score, the third receives 58%, the fourth 50% and so on (inverse square root).
By default, same site suppression uses a setting of -SSS=2. In this case sites are not distinguished below the second directory level. For example, a.b.c/d/ would be considered a separate site from a.b.c but a.b.c/d/e/ is considered part of a.b.c/d/. Same site suppression can be disabled using a setting of (-SSS=0).
The same site suppression penalty can be adjusted using the -SameSiteSuppressionExponent query processor option. Th default setting of 0.5 creates the inverse square root relation. Changing this to 0.33 for example changes the penalty function to be an inverse cube root relation. The following diagram shows how successive documents from the same site will have their scores down-weighted using several different SameSiteSupressionExponents as an example
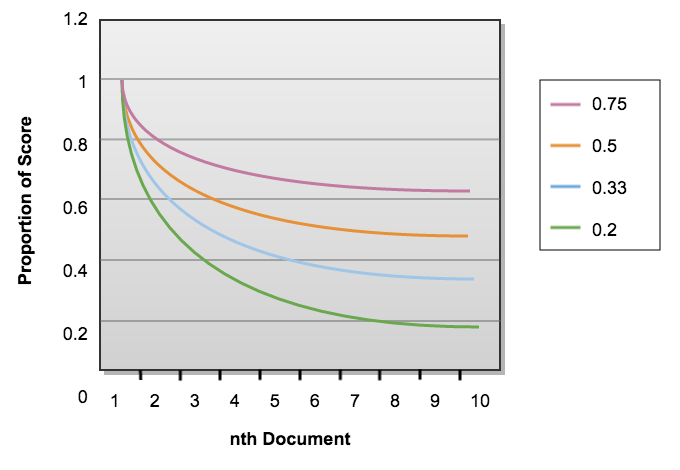
Other forms of diversification Same site suppression was the first diversification tool provided by Funnelback and was introduced in around 2002. Since then a number of additional mechanisms have been introduced to assist in avoiding undesirable homogeneity in results returned. For example, documents can be pushed down the ranking
-
(A) if they have nearly the same content as a result already presented,
-
(B) if they have the same title as a document already presented,
-
© if they come from the same component data source,
-
(D) if they repeat the same string in a nominated metadata field.
See:
Customizing Funnelback ranking
Funnelback’s default settings will work well for most organizations, but result quality can usually be improved by tuning Funnelback to suit your organizations particular information characteristics. Funnelback default settings have arisen out of optimisation experiments, using hundreds of queries and thousands of combinations of settings, using a gradient-based optimisation framework. As noted above, unless you know what you are doing, changing defaults on the basis of intuition is likely to make things worse!
Measuring result quality
Funnelback provides an interface for creating sets of test queries and expected answers, and can produce quality measurements for your site. The measurement system is an essential component of automated tuning.
Please be aware that the selection of test queries is crucial to producing good results, and simply selecting the most popular queries for a site introduces a bias which may substantially harm the result quality of less frequent queries if the set is used as the basis for tuning.
Changing scoring mode using -sco query processor option
-
The default setting for the Funnelback scoring mode is scoring mode 2 (
-sco=2) and it results in the behaviour described above. By default matches in metadata fields k (anchortext), K (clicked queries) and t (titles) are implicitly included. -
You can augment this mode to change the list of implicitly included metadata fields. For example,
-sco=2[k]to avoid implicitly including clicked queries and titles.-sco=2[source,coverage,publisher,function]would implicitly include source, coverage, publisher, and function instead of anchor text, and title. See: controlling metadata field weighting. -
You can also turn off all the implicit metadata and anchor text scoring by selecting scoring mode 0 (
-sco=0). -
A final mode is
-sco=1which produces an unordered set of results instead of a ranked list. This may be appropriate if the results are to be consumed by an application where ranking is not required.-sco=1may be a little faster than-sco=0.