Implementer training - Working with XML content
Funnelback can index XML documents and there are some additional configuration files that are applicable when indexing XML files.
-
You can map elements in the XML structure to Funnelback metadata classes.
-
You can display cached copies of the document via XSLT processing.
Funnelback can be configured to index XML content, creating an index with searchable, fielded data.
Funnelback metadata classes are used for the storage of XML data – with configuration that maps XML element paths to internal Funnelback metadata classes – the same metadata classes that are used for the storage of HTML page metadata. An element path is a simple XML X-Path.
XML files can be optionally split into records based on an X-Path. This is useful as XML files often contain a number of records that should be treated as individual result items.
Each record is then indexed with the XML fields mapped to internal Funnelback metadata classes as defined in the XML mappings configuration file.
XML configuration
The data source’s XML configuration defines how Funnelback’s XML parser will process any XML files that are found when indexing.
The XML configuration is made up of two parts:
-
XML special configuration
-
Metadata classes containing XML field mappings
The XML parser is used for the parsing of XML documents and also for indexing of most non-web data. The XML parser is used for:
-
XML, CSV and JSON files,
-
Database, social media, directory, HP CM/RM/TRIM and most custom data sources.
XML element paths
Funnelback element paths are simple X-Paths that select on fields and attributes.
Absolute and unanchored X-Paths are supported, however for some special XML fields absolute paths are required.
-
If the path begins with
/then the path is absolute (it matches from the top of the XML structure). -
If the path begins with
//it is unanchored (it can be located anywhere in the XML structure).
XML attributes can be used by adding @attribute to the end of the path.
Element paths are case sensitive.
| Attribute values are not supported in element path definitions. |
Example element paths:
| X-Path | Valid Funnelback element path |
|---|---|
|
VALID |
|
VALID |
|
VALID |
|
VALID |
|
NOT VALID |
Interpretation of field content
CDATA tags can be used with fields that contain reserved characters or the characters should be HTML encoded.
Fields containing multiple values should be delimited with a vertical bar character or the field repeated with a single value in each repeated field.
For example: The indexed value of //keywords/keyword and //subject below would be identical.
<keywords>
<keyword>keyword 1</keyword>
<keyword>keyword 2</keyword>
<keyword>keyword 3</keyword>
</keywords>
<subject>keyword 1|keyword 2|keyword 3</subject>XML special configuration
There are a number of special properties that can be configured when working with XML files. These options are defined from the XML configuration screen, by selecting configure XML processing from the settings panel on the data source management screen.

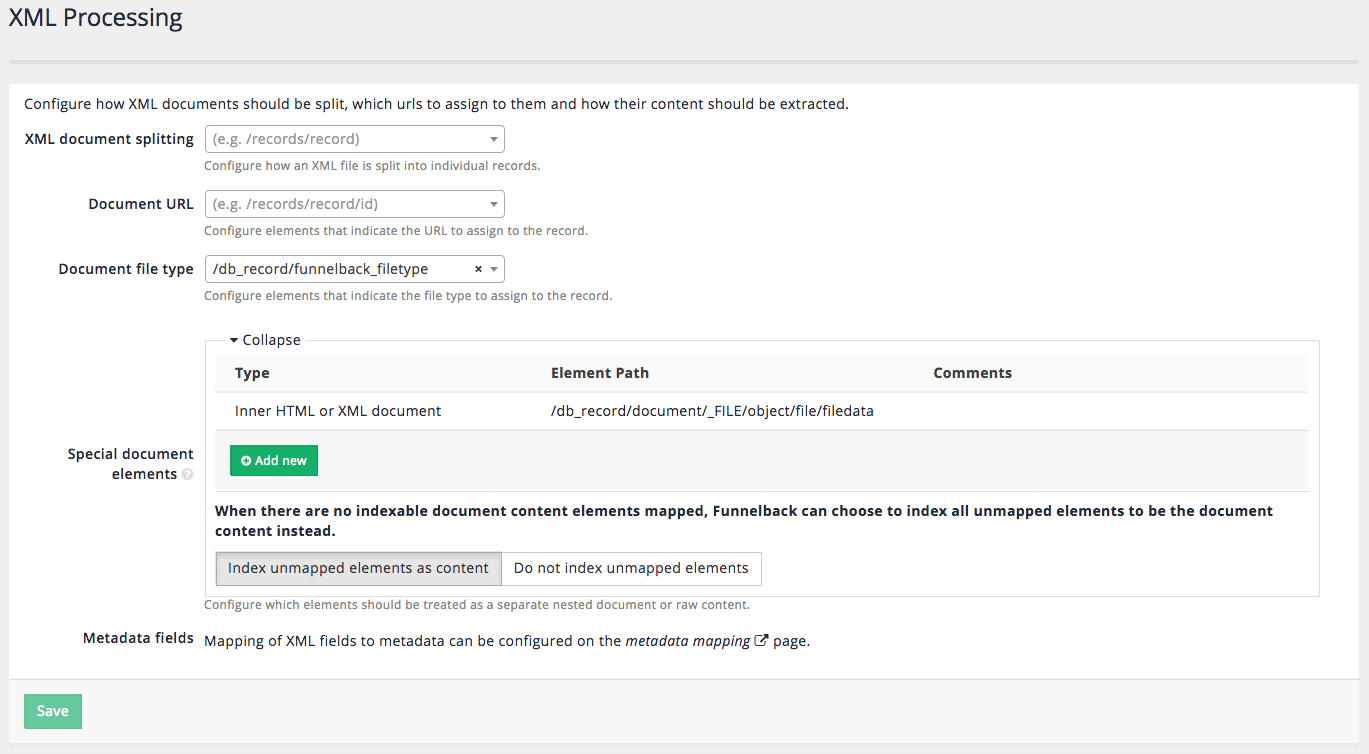
XML document splitting
A single XML file is commonly used to describe many items. Funnelback includes built-in support for splitting an XML file into separate records.
Absolute X-Paths must be used and should reference the root element of the items that should be considered as separate records.
| Splitting an XML document using this option is not available on push indexes. A filter can be used as an alternative approach for splitting documents when using a push index. |
Document URL
The document URL field can be used to identify XML fields containing a unique identifier that will be used by Funnelback as the URL for the document. If the document URL is not set then Funnelback auto-generates a URL based on the URL of the XML document. This URL is used by Funnelback to internally identify the document, but is not a real URL.
|
Setting the document URL to an XML attribute is not supported. Setting a document url is not available on push collections. |
Document file type
The document file type field can be used to identify an XML field containing a value that indicates the filetype that should be assigned to the record. This is used to associate a file type with the item that is indexed. XML records are commonly used to hold metadata about a record (for example, from a records management system) and this may be all the information that is available to Funnelback when indexing a document from such as system.
Special document elements
The special document elements can be used to tell Funnelback how to handle elements containing content.
Inner HTML or XML documents
The content of the XML field will be treated as a nested document and parsed by Funnelback and must be XML encoded (i.e. with entities) or wrapped in a CDATA declaration to ensure that the main XML document is well-formed.
The indexer will guess the nested document type and select the appropriate parser:
The nested document will be parsed as XML if (once decoded) it is well-formed XML and starts with an XML declaration similar to <?xml version="1.0" encoding="UTF-8" />. If the inner document is identified as XML it will be parsed with the XML parser and any X-Paths of the nested document can also be mapped. Note: the special XML fields configured on the advanced XML processing screen do not apply to the nested document. For example, this means you can’t split a nested document.
The nested document will be parsed as HTML if (once decoded) when it starts with a root <html> tag. Note that if the inner document contains HTML entities but doesn’t start with a root <html> tag, it will not be detected as HTML. If the inner document is identified as HTML and contains metadata then this will be parsed as if it was an HTML document, with embedded metadata and content extracted and associated with the XML records. This means that metadata fields included in the embedded HTML document can be mapped in the metadata mappings along with the XML fields.
The inner document in the example below will not be detected as HTML:
<root>
<name>Example</name>
<inner>This is <strong>an example</strong></inner>
</root>This one will:
<root>
<name>Example</name>
<inner><html>This is <strong>an example</strong></html></inner>
</root>Indexable document content
Any listed X-Paths will be indexed as un-fielded document content - this means that the content of these fields will be treated as general document content but not mapped to any metadata class (similar to the non-metadata field content of an HTML file).
For example, if you have the following XML document:
<?xml version="1.0" encoding="UTF-8"?>
<root>
<title>Example</title>
<inner>
<![CDATA[
<html>
<head>
<meta name="author" content="John Smith">
</head>
<body>
This is an example
</body>
</html>
]]>
</inner>
</root>With an Indexable document content path to //root/inner, the document content will have This is an example; however, the metadata author will not be mapped to "John Smith". To have the metadata mapped as well, the Inner HTML or XML document path should be used instead.
Include unmapped elements as content
If there are no indexable document content paths mapped, Funnelback can optionally choose to how to handle the unmapped fields. When this option is selected then all unmapped XML fields will be considered part of the general document content.
Tutorial: Creating an XML data source
In this exercise you will create a searchable index based off records contained within an XML file.
A web data source is used to create a search of a content sourced by crawling one or more websites. This can include the fetching of one or more specific URLs for indexing.
For this exercise we will use a web data source, though XML content can exist in many different data sources types (for example, custom, database, directory, social media).
The XML file that we will be indexing includes a number of individual records that are contained within a single file, an extract of which is shown below.
<?xml version="1.0" encoding="UTF-8"?>
<tsvdata>
<row>
<Airport_ID>1</Airport_ID>
<Name>Goroka</Name>
<City>Goroka</City>
<Country>Papua New Guinea</Country>
<IATA_FAA>GKA</IATA_FAA>
<ICAO>AYGA</ICAO>
<Latitude>-6.081689</Latitude>
<Longitude>145.391881</Longitude>
<Altitude>5282</Altitude>
<Timezone>10</Timezone>
<DST>U</DST>
<TZ>Pacific/Port_Moresby</TZ>
<LATLONG>-6.081689;145.391881</LATLONG>
</row>
<row>
<Airport_ID>2</Airport_ID>
<Name>Madang</Name>
<City>Madang</City>
<Country>Papua New Guinea</Country>
<IATA_FAA>MAG</IATA_FAA>
<ICAO>AYMD</ICAO>
<Latitude>-5.207083</Latitude>
<Longitude>145.7887</Longitude>
<Altitude>20</Altitude>
<Timezone>10</Timezone>
<DST>U</DST>
<TZ>Pacific/Port_Moresby</TZ>
<LATLONG>-5.207083;145.7887</LATLONG>
</row>
<row>
<Airport_ID>3</Airport_ID>
<Name>Mount Hagen</Name>
<City>Mount Hagen</City>
<Country>Papua New Guinea</Country>
<IATA_FAA>HGU</IATA_FAA>
...Indexing an XML file like this requires two main steps:
-
Configuring Funnelback to fetch and split the XML file
-
Mapping the XML fields for each record to Funnelback metadata classes.
Exercise steps
-
Log in to the search dashboard where you are doing your training.
See: Training - search dashboard access information if you’re not sure how to access the training. Ignore this step if you’re treating this as a non-interactive tutorial. -
Create a new search package named
Airports. -
Add a web data source to this search package with the following attributes:
- Type
-
web
- Name
-
Airports data - What website(s) do you want to crawl?
-
https://docs.squiz.net/training-resources/airports/airports.xml
-
Update the data source.
-
Create a results page (as part of the Airports search package) named
Airport finder. -
Run a search for !showall using the search preview. Observe that only one result (to the source XML file) is returned.
if you place an exclamation mark before a word in a query this negates the term and the results will include items that don’t contain the word. For example, !showall, used in the example above, means return results that do not contain the word showall.
-
Configure Funnelback to split the XML files into records. To do this we need to inspect the XML file(s) to see what elements are available.
Ideally you will know the structure of the XML file before you start to create your collection. However, if you don’t know this and the XML file isn’t too large you might be able to view it by inspecting the cached version of the file, available from the drop down link at the end of the URL. If the file is too large the browser may not be able to display the file. Inspecting the XML (displayed above) shows that each airport record is contained within the
<row>element that is nested beneath the top level<tsvdata>element. This translates to an X-Path of/tsvdata/row.Navigate to the manage data source screen and select configure XML processing from the settings panel. The XML processing screen is where all the special XML options are set.
-
The XML document splitting field configures the X-Path(s) that are used to split an XML document. Select
/tsvdata/rowfrom the listed fields.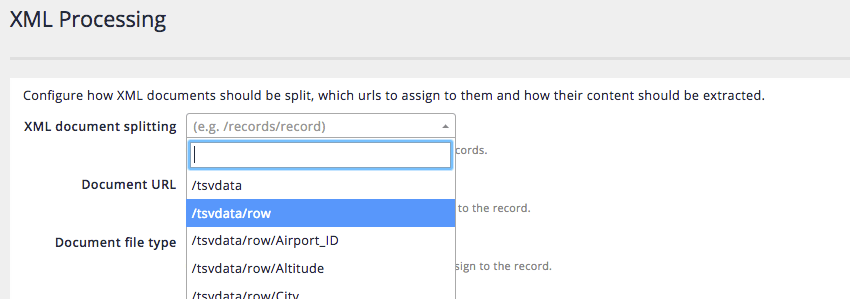
-
If possible also set the document URL to an XML field that contains a unique identifier for the XML record. This could be a real URL, or some other sort of ID. Inspecting the airports XML shows that the Airport_ID can be used to uniquely identify the record. Select
/tsvdata/row/Airport_IDfrom the dropdown for the document URL field.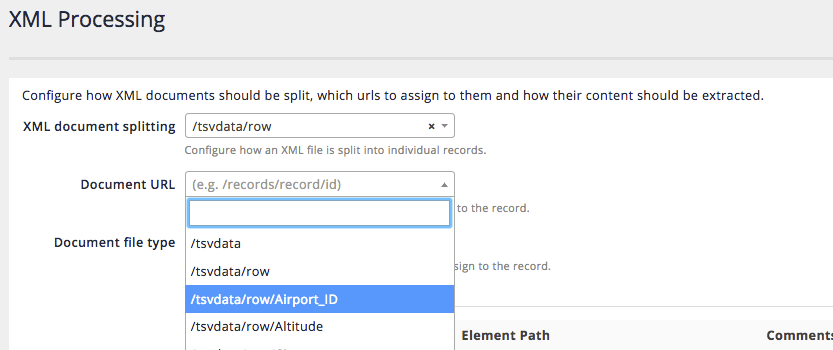
If you don’t set a document URL Funnelback will automatically assign a URL. -
Leave the other fields unchanged then click the save button.
-
The index must be rebuilt for any XML processing changes to be reflected in the search results. Return to the manage data source screen then rebuild the index by selecting start advanced update from the update panel, then selecting rebuild live index.
-
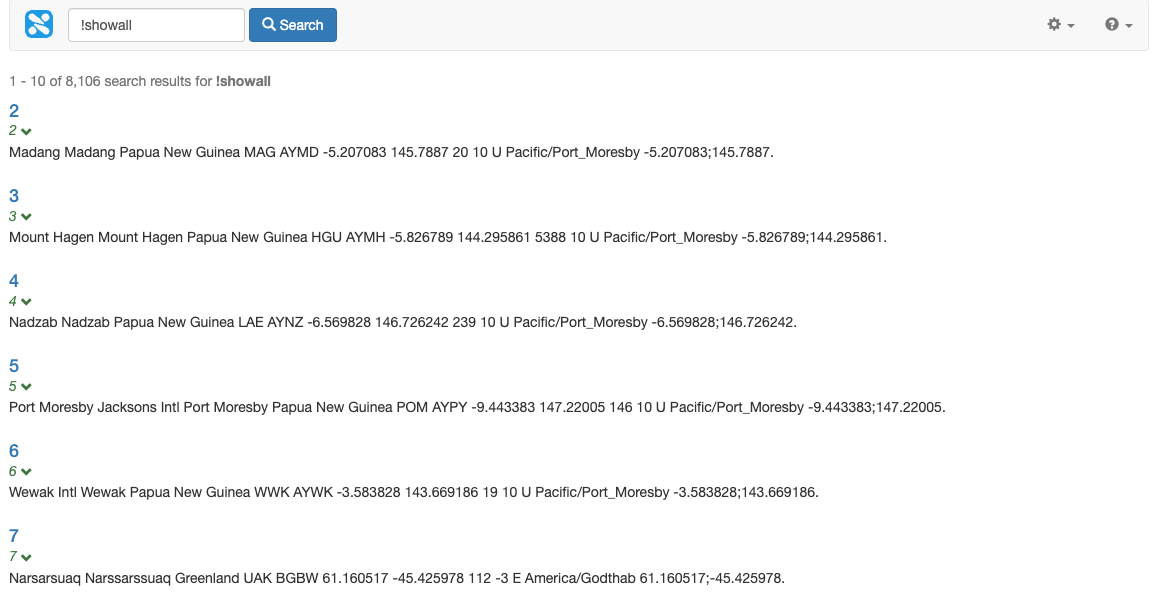
Run a search for !showall using the search preview and confirm that the XML file is now being split into separate items. The search results display currently only shows the URLs of each of the results (which in this case is just an ID number). In order to display sensible results the XML fields must be mapped to metadata and displayed by Funnelback.
-
Map XML fields by selecting configure metadata mappings from the settings panel.
-
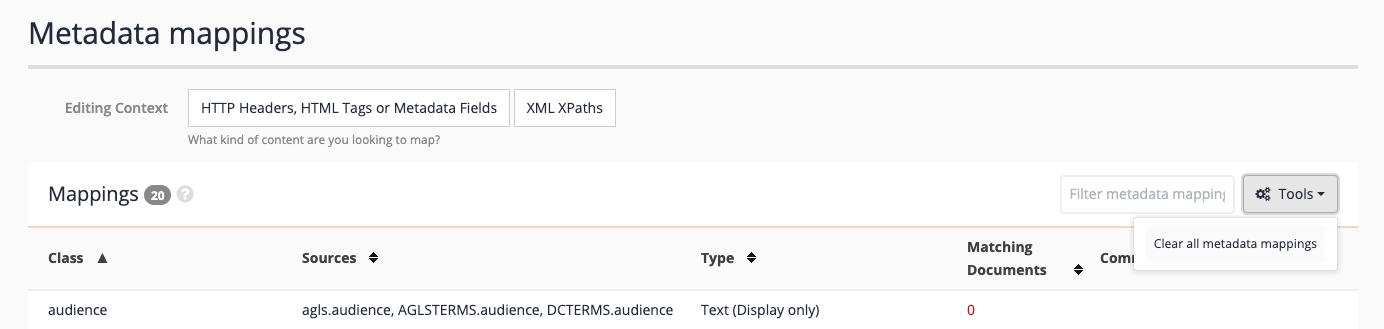
The metadata screen lists a number of pre-configured mappings. Because this is an XML data set, the mappings will be of no use so clear all the mappings by selecting clear all metadata mappings from the tools menu.
-
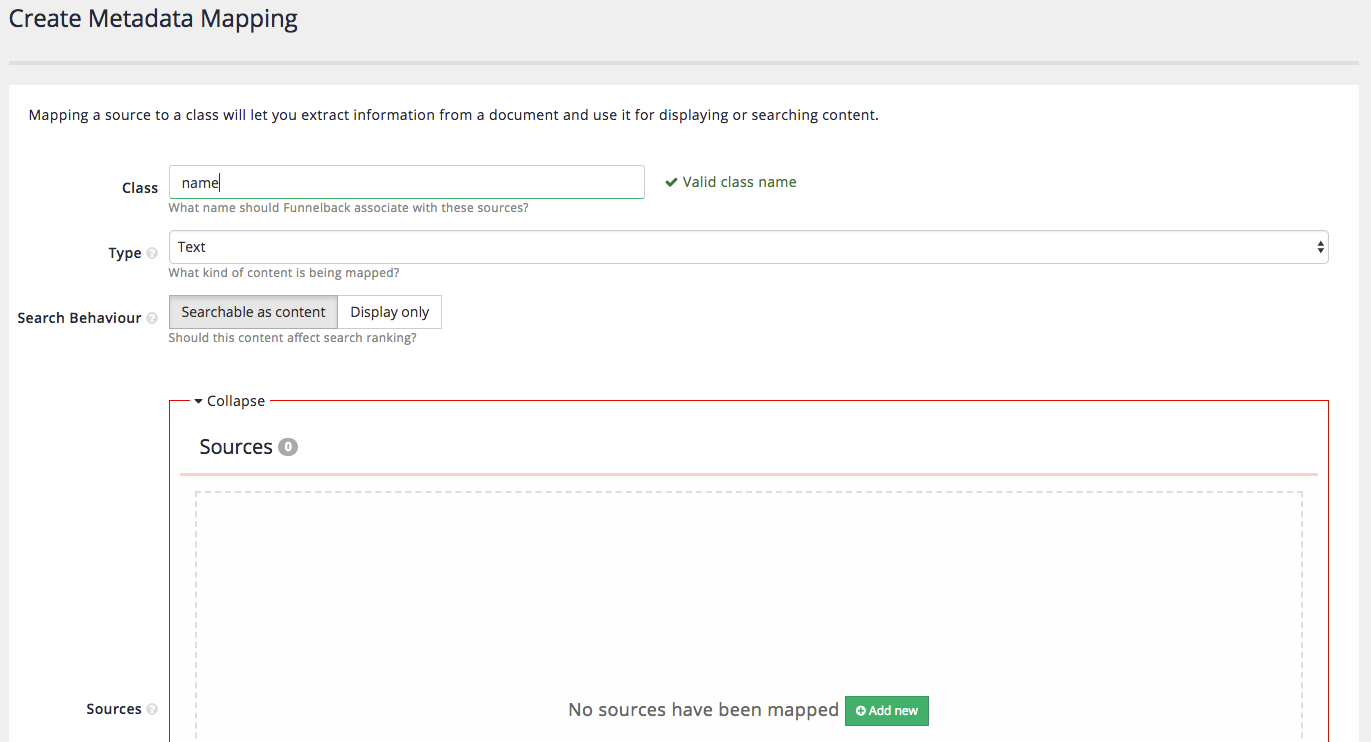
Click the add new button to add a new metadata mapping. Create a class called name that maps the
<Name>xml field. Enter the following into the creation form:- Class
-
name - Type
-
Text
- Search behavior
-
Searchable as content
-
Add a source to the metadata mapping. Click the add new button in the sources box. This opens up a window that displays the metadata sources that were detected when the index was built. Display the detected XML fields by clicking on the XML path button for the type of source, then choose the Name (
/tsvdata/row/Name) field from the list of available choices the click the save button.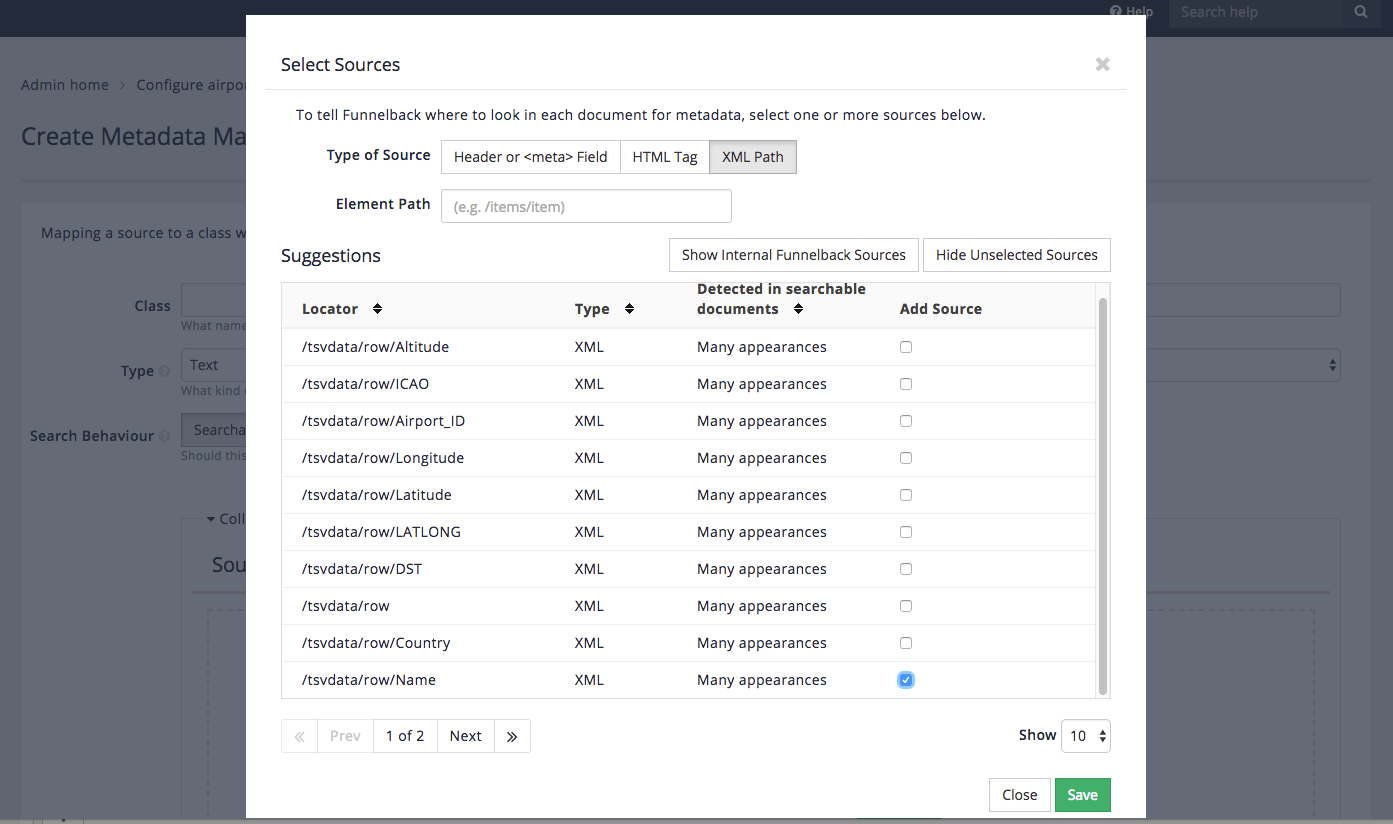
-
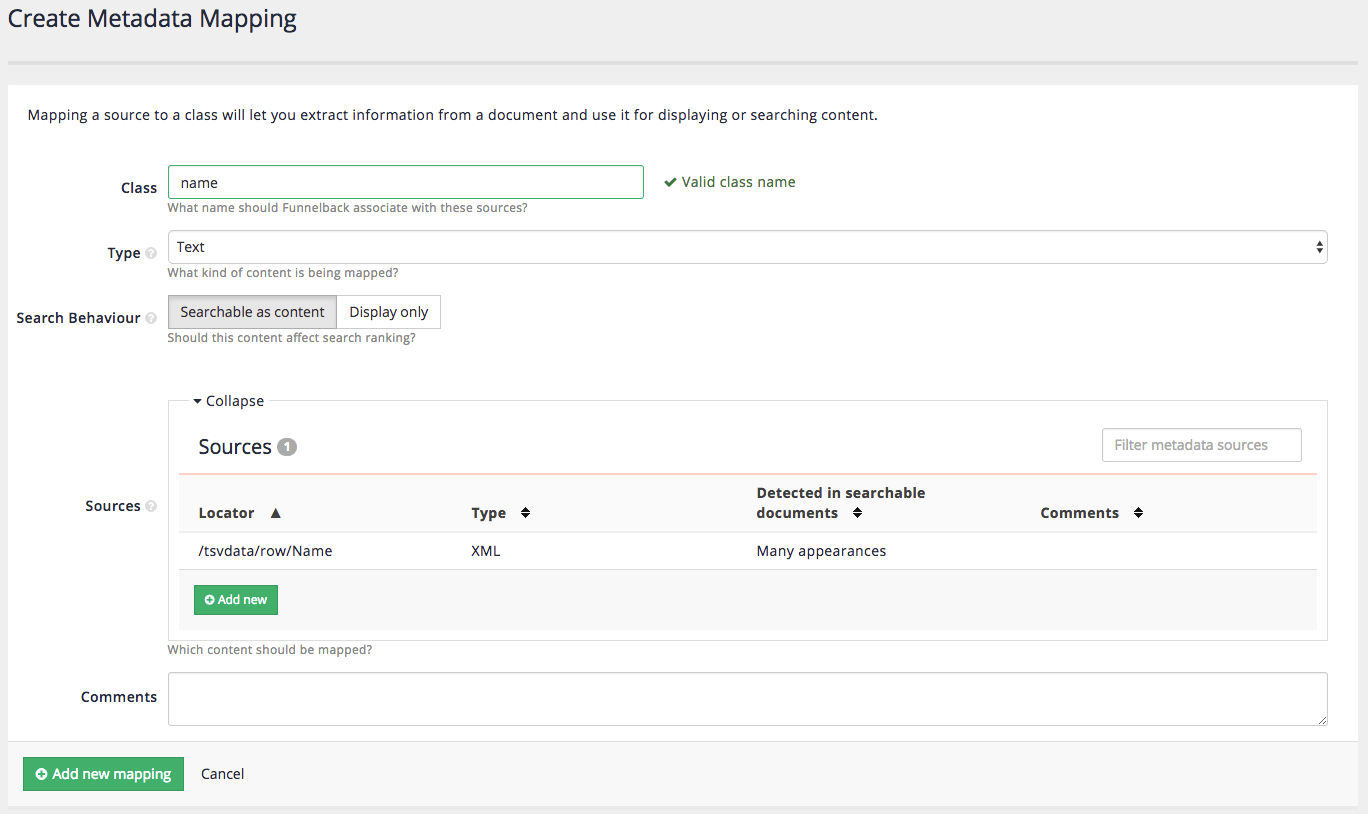
You are returned to the create mapping screen. Click the add new mapping button to create the mapping.
-
The metadata mappings screen updates to show the newly created mapping for Name.
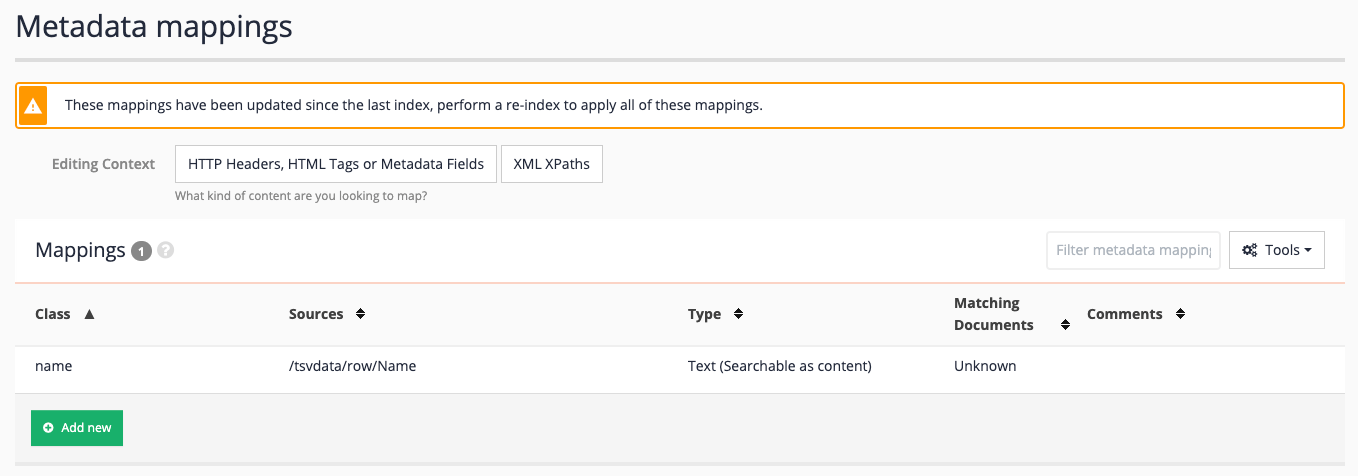
-
Repeat the above process to add the following mappings. Before adding the mapping switch the editing context to XML - this will mean that XML elements are displayed by default when selecting the sources.

Class name Source Type Search behaviour city/tsvdata/row/Citytext
searchable as content
country/tsvdata/row/Countrytext
searchable as content
iataFaa/tsvdata/row/IATA_FAAtext
searchable as content
icao/tsvdata/row/ICAOtext
searchable as content
altitude/tsvdata/row/Altitudetext
searchable as content
latlong/tsvdata/row/LATLONGtext
display only
latitude/tsvdata/row/Latitudetext
display only
longitude/tsvdata/row/Longitudetext
display only
timezone/tsvdata/row/Timezonetext
display only
dst/tsvdata/row/DSTtext
display only
tz/tsvdata/row/TZtext
display only
-
Note that the metadata mappings screen is displaying a message:
These mappings have been updated since the last index, perform a re-index to apply all of these mappings.
Rebuild the index by navigating to the manage data source screen then selecting start advanced update from the settings panel. Select rebuild live index from the rebuild live index section and click the update button.
-
Display options will need to be configured so that the metadata is returned with the search results. Reminder: this needs to be set up on the airport finder results page. Edit the results page configuration, and add summary fields to include the name, city, country, iataFaa, icao and altitude metadata to the query processor options:
-stem=2 -SF=[name,city,country,iataFaa,icao,altitude] -
Rerun the search for !showall and observe that metadata is now returned for the search result.
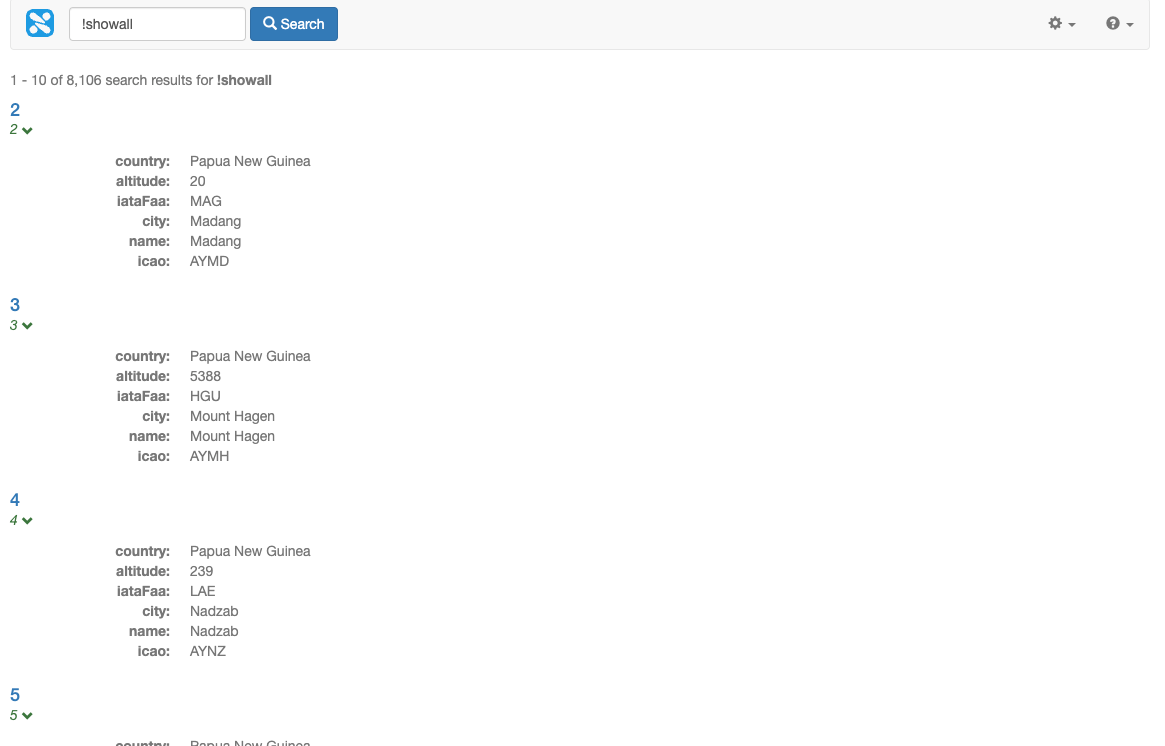
-
Inspect the data model. Reminder: edit the url changing
search.htmltosearch.json. Inspect the response element - each result should have fields populated inside thelistMetadatasub elements of the result items. These can then be accessed from your Freemarker template and printed out in the search results.