Implementer training - Configure a search package
Search packages
Understanding how search packages combine indexes
It is important to understand a few basics about how search packages aggregate content from the different data sources.
-
Metadata classes of all included data sources are combined: this means if you have a class called title in data source A and a class called title in data source B there will be a field called title in the search package that searches the title metadata from both data sources. This means you need to be careful about the names you choose for your metadata classes, ensuring that they only overlap when you intend them to. One technique you can use to avoid this is to namespace your metadata fields to keep them separate. (for example, use something like
websiteTitleinstead oftitlein your website data source). -
Generalized scopes of all included data sources are combined: the same principles as outlined above for metadata apply to gscopes. You can use gscopes to combine or group URLs across data sources by assigning using the same gscope ID in each data source, but only do this when it makes sense - otherwise you may get results that you don’t want if you choose to scope the search results using your defined gscopes.
-
Geospatial and numeric metadata: these are special metadata types and the value of the fields are interpreted in a special way. If you have any of these classes defined in multiple data sources ensure they are of the same type where they are defined.
-
Search packages combine the indexes at query time: this means you can add and remove data sources from the search package and immediately start searching across the indexes.
auto-completion and spelling suggestions for the search package won’t be updated to match the changed search package content until one of the data sources completes a successful update. -
You can scope a query only return information from specific data sources within a search package by supplying the
cliveparameter with a list of data sources to include. -
If combined indexes contain an overlapping set of URLs then duplicates will be present in the search results (as duplicates are not removed at query time).
Configuring search packages
There are a few things that must be considered when configuring search packages - this is due to the separation between the querying of the search packages and the fact that the indexes for included data sources are not directly part of the search package.
Results pages are used to configure the different searches provided by the search package and configuration for most query-time behaviour needs to be made on the results page. Because results pages part of a search package, they inherit configuration from the search package.
Items that should be configured on a search package include:
-
included data sources (meta components)
-
analytics
-
contextual navigation
-
quick links display
-
content auditor
-
extra searches
Items that should be configured on the results page include:
-
templates
-
synonyms, best bets and curator rules
-
faceted navigation
addition of facets based on new metadata fields or generalized scopes require the affected data sources to be updated before the facet will be visible. -
display options
-
ranking options
-
most auto-completion options
-
search lifecycle plugins
However, because the indexes are still built when the data sources update any changes that affect the update or index build process must be made in the data source configuration. These changes include:
-
metadata field mappings and external metadata
-
gscope mappings
-
indexer options
-
quicklinks generation
-
filters and filter plugins
-
spelling options
Tutorial: Define a scope for a results page
When a new results page is created it has the same content as the parent search package.
Results pages are commonly used to provide a search across a sub-set of content within the search package. To achieve this the results page should be configured to apply a default scope.
In this exercise the Shakespeare search results page will be scoped so that only URLs from the Shakespeare website are returned when the running searches using the Shakespeare search results page.
The Shakespeare search results page is selected by passing a profile parameter set to the results page ID (shakespeare-search) in the search query.
-
Log in to the search dashboard where you are doing your training.
See: Training - search dashboard access information if you’re not sure how to access the training. Ignore this step if you’re treating this as a non-interactive tutorial. -
Locate the library search package.
-
Create another results page, but this time call the results page Shakespeare search.
-
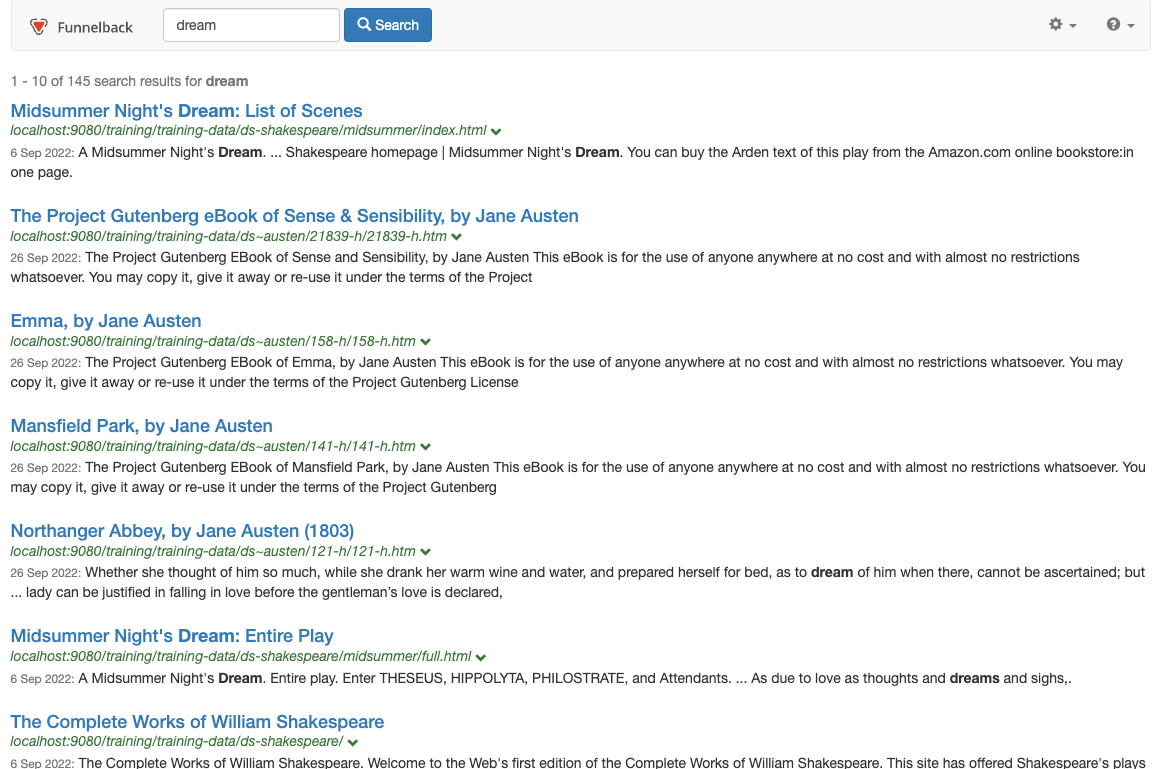
Run a search for dream ensuring the preview option is selected and observe that pages from both the Shakespeare and Austen sites are returned.

-
Select edit results page configuration from the customize section. The index can be scoped by setting an additional query processor option.
Query processor options are settings that can are applied dynamically to a Funnelback search when a query is made to the search index. The options can control display, ranking and scoping of the search results and can be varied for each query that is run. -
Add a query processor option to scope the results page - various options can be used to scope the results page including
scope,xscope,gscope1andclive. Thecliveparameter is a special scoping parameter that can be applied to results page to restrict the results to only include pages from a specified data source or set of data sources. The clive parameter takes a list of data source IDs to include in the scoped set of data. Add acliveparameter to scope the results page to pages from the training~ds-shakespeare data source then click the save button, (but do not publish) the file. You can find the data source ID in the information panel at the top of the results page management screen.-clive=training~ds-shakespeare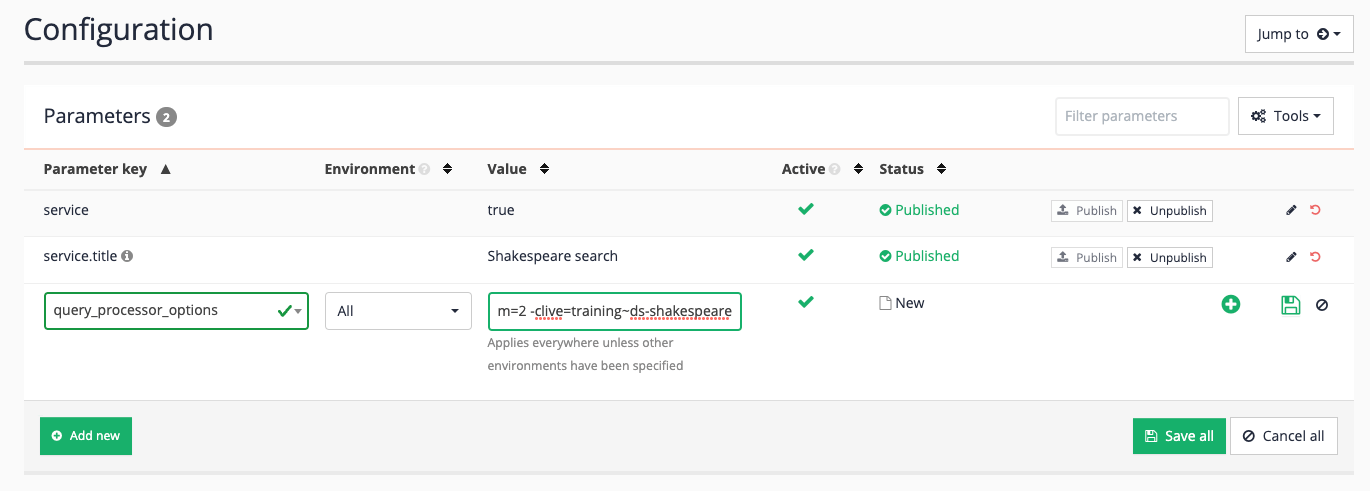
-
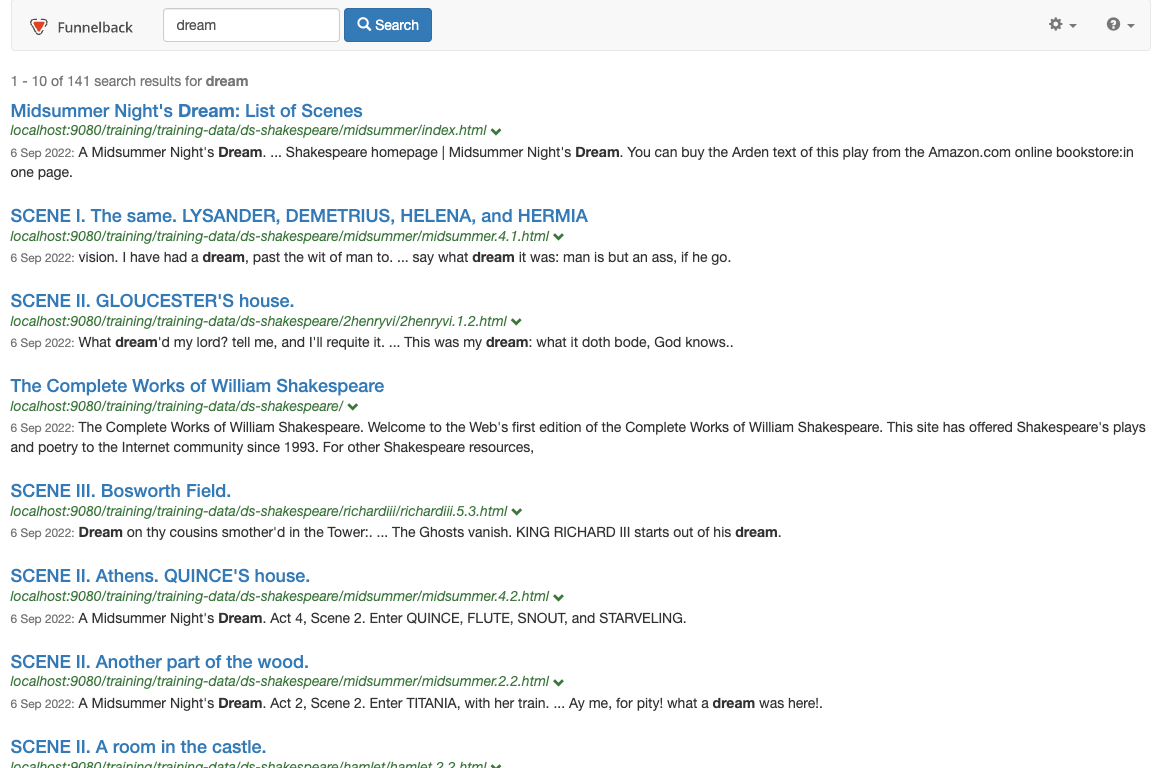
Rerun the search for dream against the preview version of the Shakespeare search results page and observe that the results are now restricted to only pages from the Shakespeare site.

-
Rerun the search for dream against the live version of the Shakespeare search results page. Observe that pages are returned from both sites - this is because the query processor options must be published for the changes to take effect on the live version of the results page.
-
Edit results page configuration again, and publish the query processor options to make the setting affect the live version of the results page.
-
Rerun the search for dream against the Shakespeare search results page. Observe that pages are now restricted to Shakespeare site pages.
Tutorial: Set default results page display and ranking options
Display and ranking (and scoping) options can be set independently for each results page.
This allows the same search package to be used to serve search results with quite different ranking/display options or to be scoped to a subset of the search package’s included data. These options are set in the same way as the scoping from the previous exercise by adding options to the query processor options.
-
Log in to the search dashboard where you are doing your training.
See: Training - search dashboard access information if you’re not sure how to access the training. Ignore this step if you’re treating this as a non-interactive tutorial. -
Navigate to the Shakespeare search results page
-
Select edit results page configuration from the customize section that was edited in the previous exercise. Set the results page to return five results per page and sort alphabetically then save and publish the changes.
-clive=training~ds-shakespeare -sort=title -num_ranks=5 -
Rerun the search for dream against the Shakespeare search results page specifying and observe that the results are sorted alphabetically by title and only 5 results are returned per page. Results are all from the Shakespeare website.