Getting started with the data model
This section provides an introduction to the more useful elements in the data model and is a great place to start when figuring out how to integrate your own application with Funnelback’s JSON or XML output.
Details
The data model is the structure returned by the JSON (search.json) and XML (search.xml) endpoints. The three main top-level nodes are:
question-
contains all the input parameters needed to run the search
response-
contains the search results and associated data (facets, etc.)
error-
contains an error message if the search failed
This page gives an overview of the most commonly fields used withing the question and response nodes, needed to implement a standard search results page when integrating with the JSON or XML endpoint.
Most commonly used question fields

-
originalQuery: Search keywords as entered by the user. Useful to display messages like "10 results for originalQuery" -
collection: Includes information about the search package that is being queried. This includes the search package ID, faceted navigation definitions, included data sources. -
profile: This is the results page ID of the results page that is being queried -
form: This is the ID of the template that is applied to the search (only applicable if using the HTML search endpoint). -
inputParameters: A map of all the request/CGI parameters supplied with the query.
Most commonly used response fields

-
resultPacket: Top-level node to obtain results and more -
queryAsProcessed: The search keywords as processed by Funnelback. This could differ fromquestion.originalQueryas it will include any additional query item generated by Funnelback, such as synonyms of facet constraints. It may be preferable in some cases to use this node to display the current query being run to indicate to the user how the keywords were processed -
resultsSummary: Gives a summary of the different result counts (how many results matched, which page the use is currently on, etc.). See corresponding section below -
spell: Spelling suggestions -
results: List of results returned by the search (See following sections) -
contextualNavigation: Contextual navigation / related searches data -
facets: List of facets / filters relevant to the current search -
curator: Curator and Best Bets messages relevant to the current search
Results summary fields
The results summary contains information used to display result counts (for example, Showing result 1 - 10 out of 3,240 for <query>) and implement pagination.

-
fullyMatching: How many search results match the entire search keywords. For example with the search keywords "chocolate cake recipe", only 11 documents may match those 3 words, but 44 documents may match "recipe" -
partiallyMatching: How many search results contain some of the search keywords, but not all. -
totalMatching: The total number of search results found (fullyMatching1 +partiallyMatching2) -
estimatedCounts: Indicate if the result counts are estimated or exact. Counts may be estimated on large indexes. If that is the case, it is recommended to surface this information to the user in the front-end (for example, "About 3,200 results for <query>" as opposite to "3,214 results for <query>" where 3,214 is an estimate) -
numRanks: The number of results on each page -
currStart: The offset of the first result on the current page. For example when viewing the first page of result, this will be 1. When viewing the 3rd page, with 10 results per page (numRanks5), this will be 21 -
currEnd: Similar tocurrStart6, the offset of the last result on the current page. For example when viewing the first page of results, this will be 10. When viewing the 3rd page, with 10 results per page (numRanks), this will be 30 -
prevStart: The offset of the first result on the previous page of result. This is unset on the first result page, and for example on the 3rd result page this will be 11 -
nextStart: The offset of the first result on the next page. For example when viewing the first page of results this will be 11, and 31 on the 3rd page of results
Individual result fields
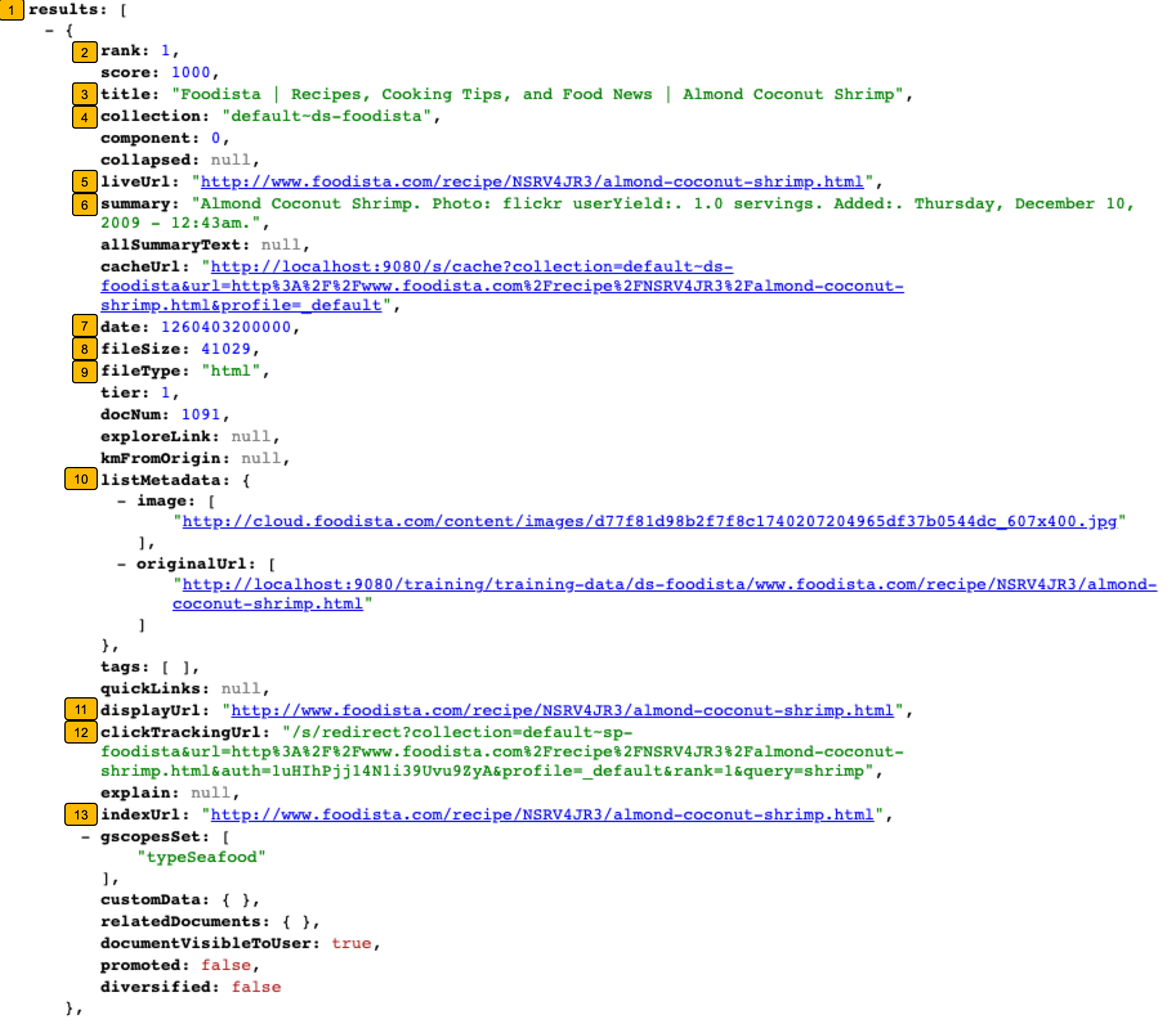
-
results: Top-level results list. Usually contains 10 results objects -
rank: This indicates the result number. -
title: Result title -
collection: This is the data source where the result was retrieved from. -
liveUrl: The URL of the result -
summary: The result summary or snippet. -
date: Timestamp associated with the result, usually from a date metadata. May be empty if no date was available -
fileSize: Result document size in bytes -
fileType: Result document type (html, pdf, docx, etc.) -
listMetadata: Key / List pair for each metadata associated with the result (for example,productCategory = ["phone","tablet"]). Each metadata field will be returned as a list of the different values that match the field. -
displayUrl: The URL to display to the user for this result. This may differ from theliveUrl5 because of internal transformations. Prefer to use this field to display the result URL in the front-end -
clickTrackingUrl: The URL to use for clicking on the result, so that Funnelback can track the click in analytics. This URL will record the click then transparently redirect the user to the original result URL. -
indexUrl: Internal URL of the result within the search index