Implementer training - ranking options
Configuring ranking
Ranking options
Funnelback’s ranking algorithm determines what results are retrieved from the index and what how the order of relevance is determined.
The ranking of results is a complex problem, influenced by a multitude of document attributes. It’s not just about how many times a word appears within a document’s content.
-
Ranking options are a subset of the query processor options which also control other aspects of query-time behaviour (such as display settings).
-
Ranking options are applied at query time - this means that different results pages can have different ranking settings applied, on an identical index. Ranking options can also be changed via CGI parameters at the time the query is submitted.
Automated tuning
Tuning is a process that can be used to determine which attributes of a document are indicative of relevance and adjust the ranking algorithm to match these attributes.
The default settings in Funnelback are designed to provide relevant results for the majority of websites. Funnelback uses a ranking algorithm, influenced by many weighted factors, that scores each document in the index when a search is run. These individual weightings can be adjusted and tuning is the recommended way to achieve this.
The actual attributes that inform relevance will vary from site to site and can depend on the way in which the content is written and structured on the website, how often content is updated and even the technologies used to deliver the website.
For example the following are examples of concepts that can inform on relevance:
-
How many times the search keywords appear within the document content
-
If the keywords appear in the URL
-
If the keywords appear in the page title, or headings
-
How large the document is
-
How recently the document has been updated
-
How deep the document is within the website’s structure
Tuning allows for the automatic detection of attributes that influence ranking in the data that is being tuned. The tuning process requires training data from the content owners. This training data is made up of a list of possible searches - keywords with what is deemed to be the URL of the best answer for the keyword, as determined by the content owners.
A training set of 50-100 queries is a good size for most search implementations. Too few queries will not provide adequate broad coverage and skew the optimal ranking settings suggested by tuning. Too many queries will place considerable load on the server for a sustained length of time as the tuning tool runs each query with different combinations of ranking settings. It is not uncommon to run in excess of 1 million queries when running tuning.
Funnelback uses this list of searches to optimize the ranking algorithm, by running each of the searches with different combinations of ranking settings and analysing the results for the settings that provide the closest match to the training data.
| Tuning does not guarantee that any of the searches provided in the training data will return as the top result. It’s purpose is to optimize the algorithm by detecting important traits found within the content, which should result in improved results for all searches. |
The tuning tool consists of two components - the training data editor and the components to run tuning.
Any user with access to the insights dashboard has the ability to edit the tuning data.
Only an administrator can run tuning and apply the optimal settings to a search.
| The running of tuning is restricted to administrators as the tuning process can place a heavy load on the server and the running of tuning needs to be managed. |
Editing training data for tuning
The training data editor is accessed from the insights dashboard by clicking on the tuning tile, or by selecting tuning from the left hand menu.
A blank training data editor is displayed if tuning has not previously been configured.
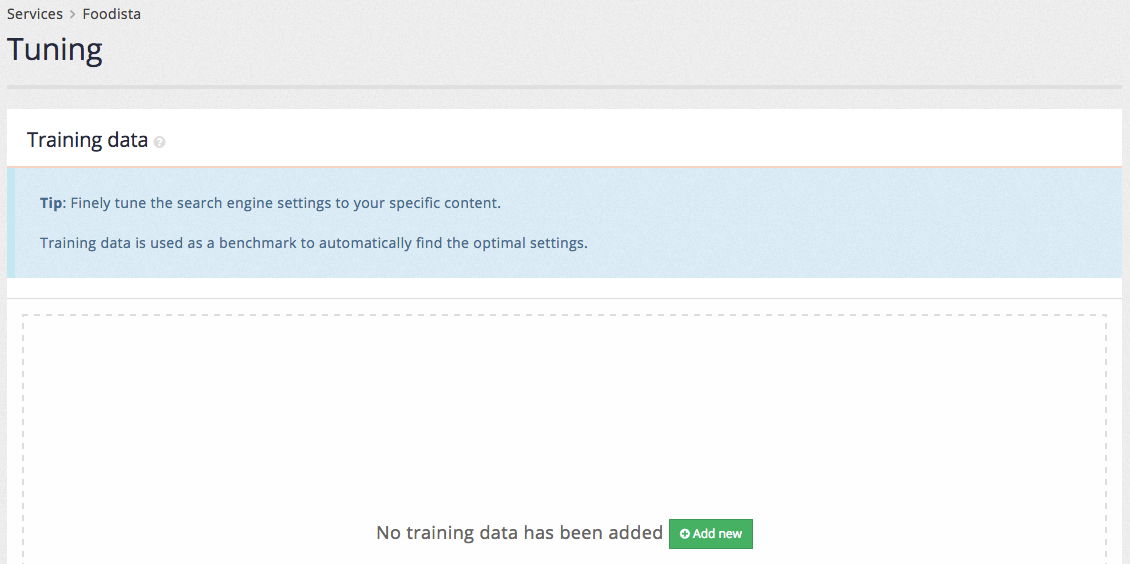
Clicking the add new button opens the editor screen.
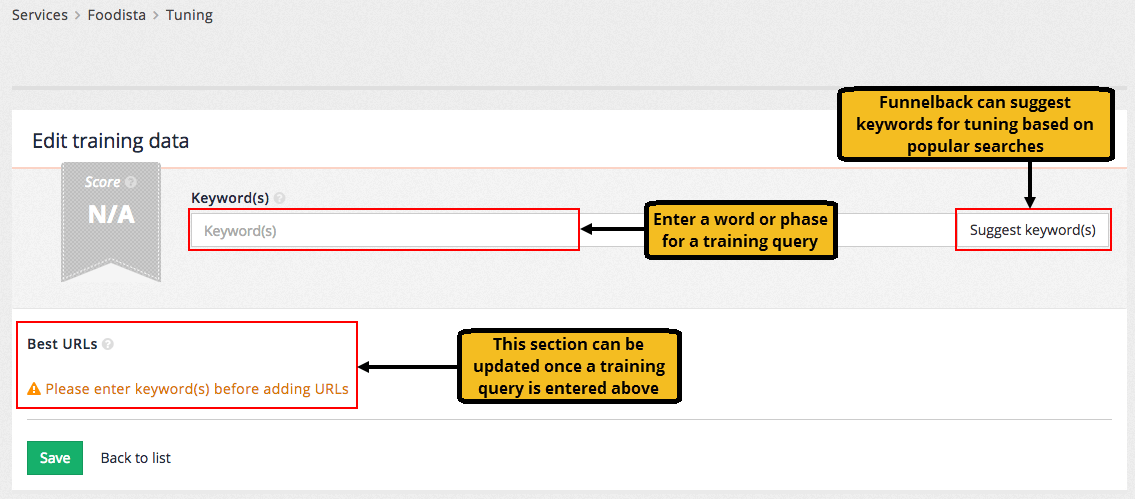
The tuning requires 50-100 examples of desirable searches. Each desirable search requires the search query and one or more URLs that represent the best answer for the query.
Two methods are available for specifying the query:
-
Enter the query directly into the keyword(s) field, or
-
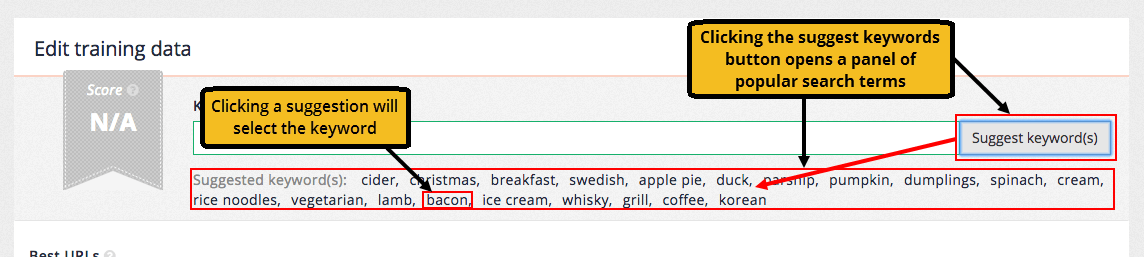
Click the suggest keyword(s) button the click on one of the suggestions that appear in a panel below the keyword(s) form field. The suggestions are randomised based on popular queries in the analytics. Clicking the button multiple times will generate different lists of suggestions.
Once a query has been input the URLs of the best answer(s) can be specified.
URLs for the best answers are added by either clicking the suggest URL to add or manually add a URL buttons.
Clicking the suggest URLs to add button opens a panel of the top results (based on current rankings).
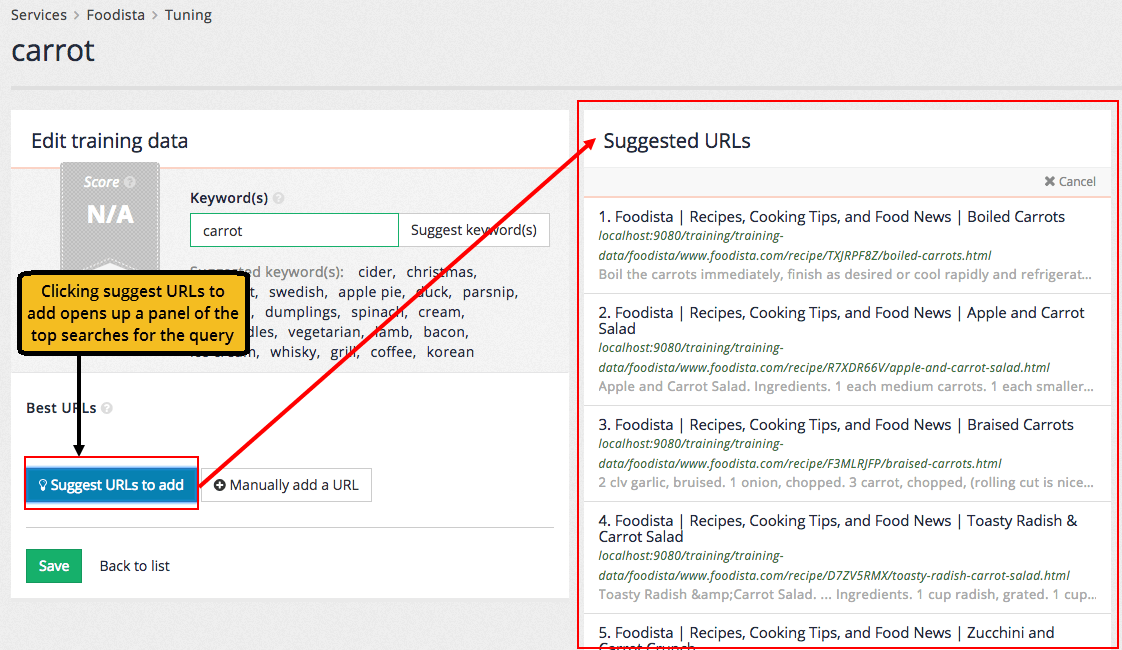
Clicking on a suggested URL adds the URL as a best answer.
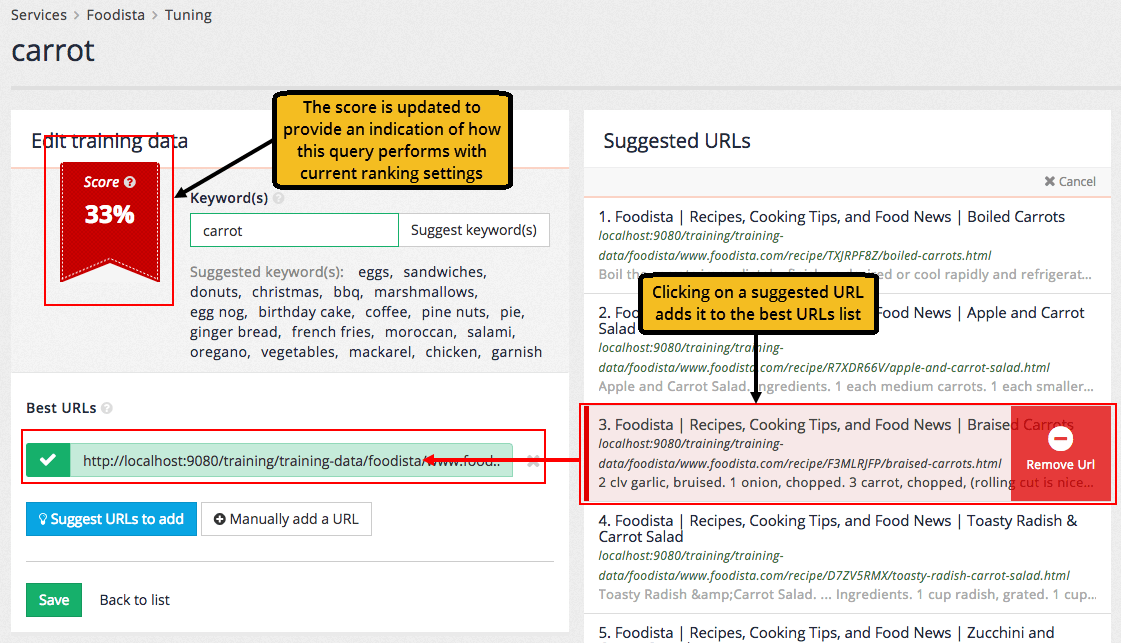
Additional URLs can be optionally added to the best URLs list - however the focus should be on providing additional query/best URL combinations over a single query with multiple best URLs.
A manual URL can be entered by clicking the manually add a URL button. Manually added URLs are checked as they are entered.
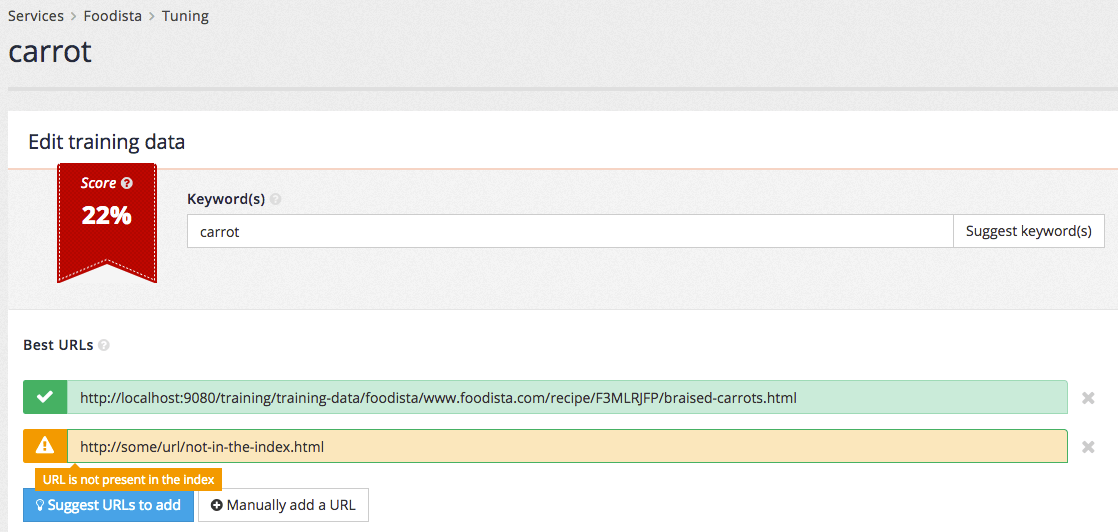
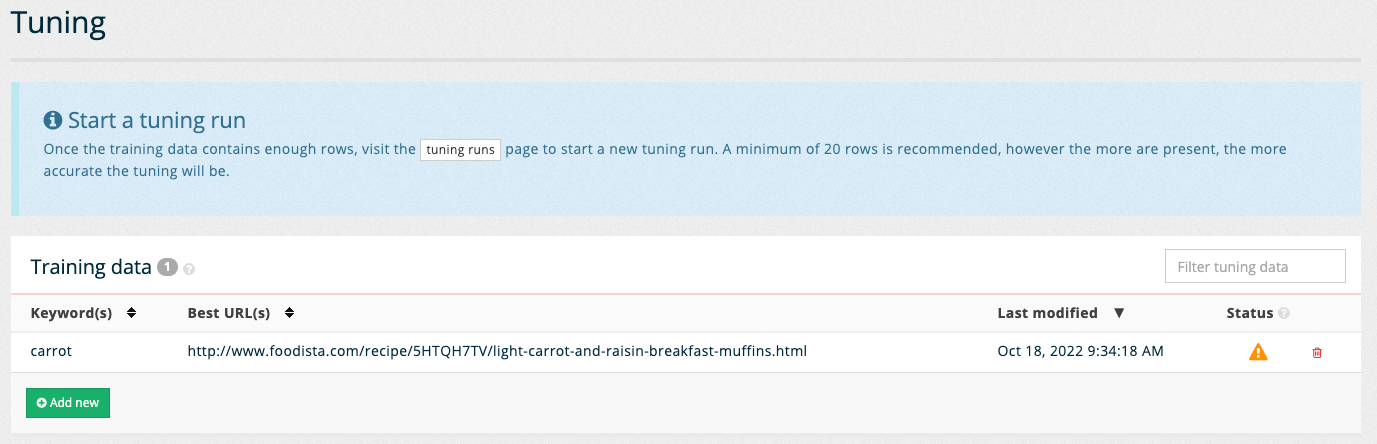
Clicking the save button adds the query to the training data. The tuning screen updates to show the available training data. Hovering over the error status icon shows that there is an invalid URL (the URL that was manually added above is not present in the search index).
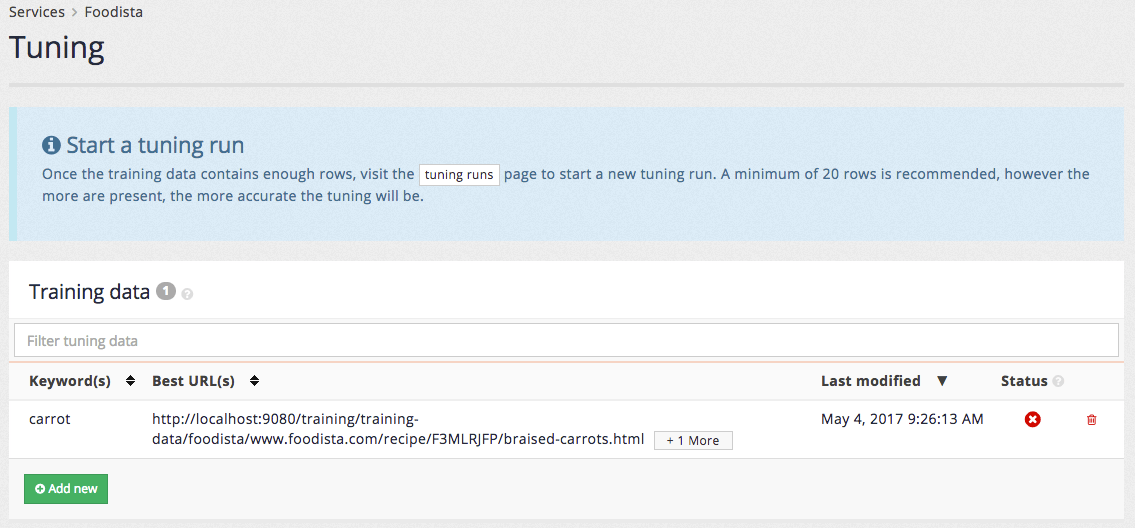
Once all the training data has been added tuning can be run.
Tuning is run from the tuning history page. This is accessed by clicking the history sub-item in the menu, or by clicking the tuning runs button that appears in the start a tuning run message.
The tuning history shows the previous tuning history for the service and also allows users with sufficient permissions to start the tuning process.
| Recall that only certain users are granted the permissions required to run tuning. |
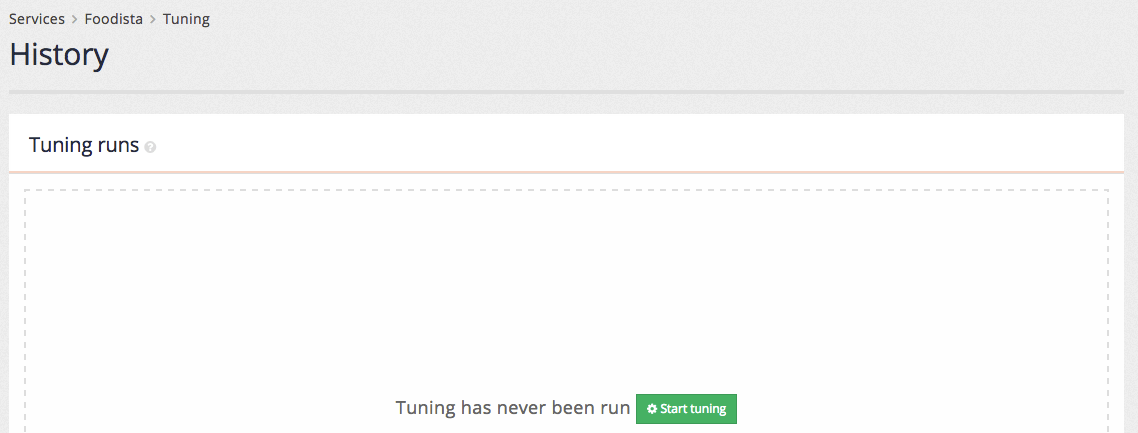
Clicking the start tuning button initiates the tuning run and the history table provides updates on the possible improvement found during the process. These numbers will change as more combinations of ranking settings are tested.
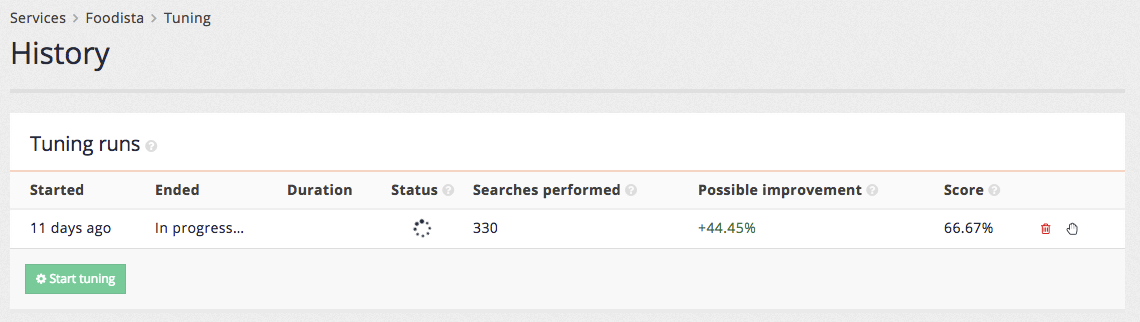
When the tuning run completes a score over time graph will be updated and the tuning runs table will hold the final values for the tuning run.
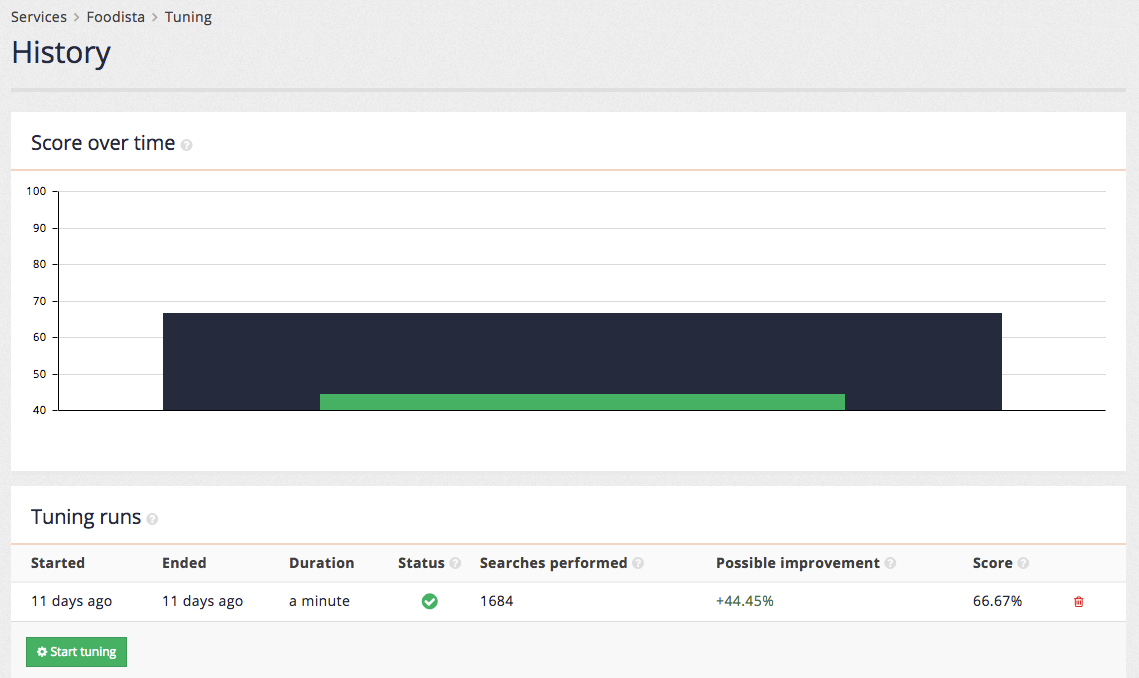
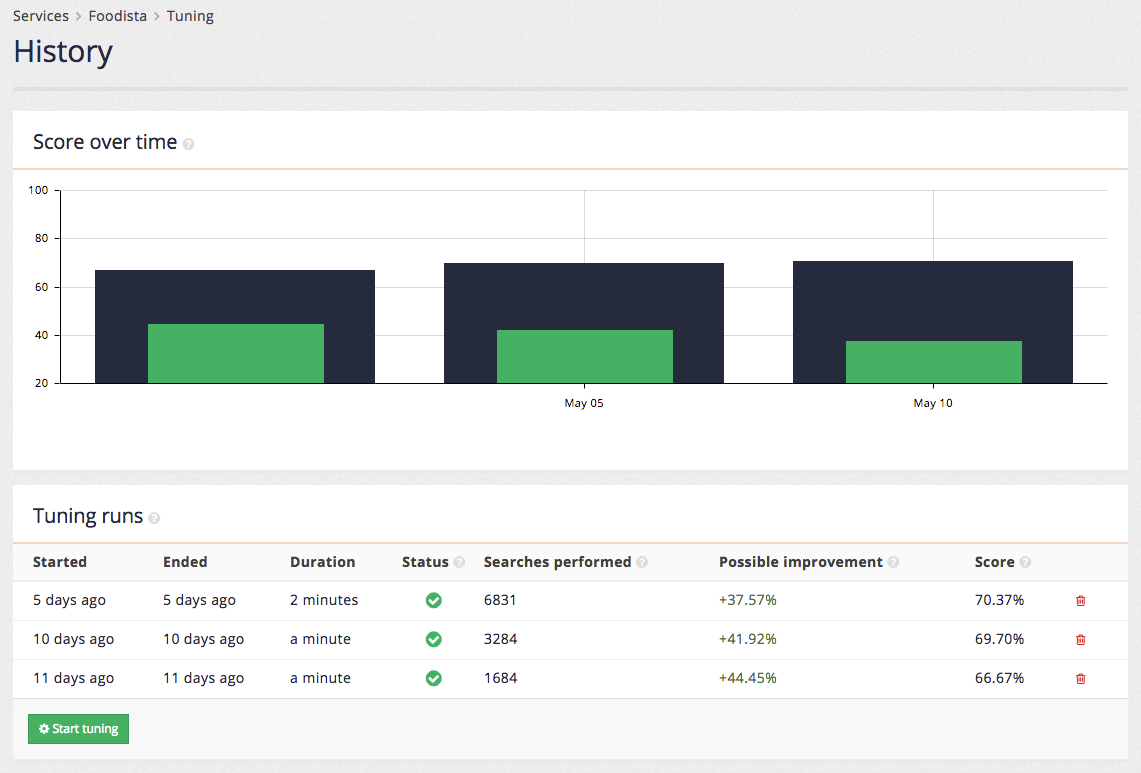
Once tuning has been run a few times additional data is added to both the score over time chart and tuning runs table.
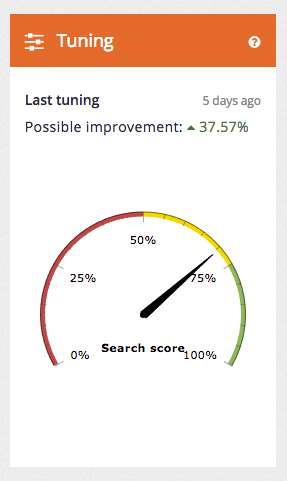
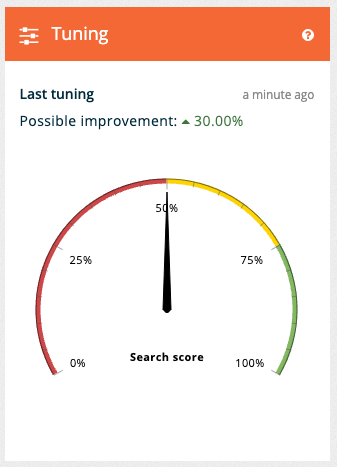
The tuning tile on the insights dashboard main page also updates to provide information on the most recent tuning run.
| The improved ranking is not automatically applied to the search. An administrator must log in to apply the optimal settings as found by the tuning process. |
Tutorial: Edit tuning data
-
Access the insights dashboard and select the foodista search results page tile. Select tuning from the left hand menu, or click on the tuning tile.
-
Alternatively, from the search dashboard open the foodista search results page management screen, and access the tuning section by selecting edit tuning data from the tuning panel.

-
The insights dashboard tuning screen opens. Click on the add new button to open up the tuning editor screen.
-
An empty edit screen loads where you can start defining the training data. Enter a query by adding a word or phrase to the keyword(s) field. Edit the value in the keyword(s) field and enter the word
carrot.You can also use the suggest keyword(s) button to receive a list of keywords that you can choose from. 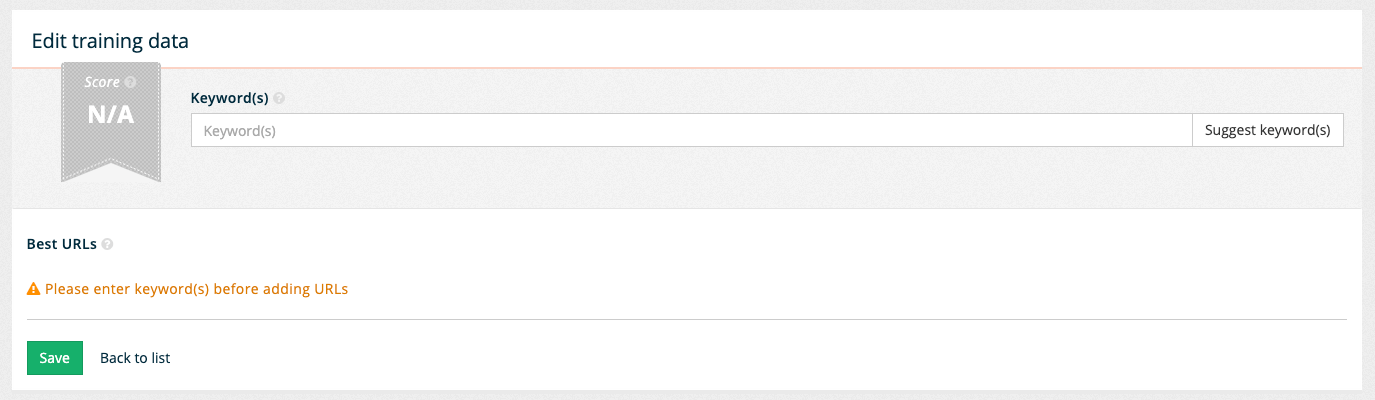
-
Observe that the best URLs panel updates with two buttons allowing the best answers to be defined. Click on the suggest URLs to add button to open a list containing of pages to choose from. Select the page that provides the best answer for a query of carrot. Note that scrolling to the bottom of the suggested URLs allows further suggestions to be loaded. Click on one of the suggested URLs, such as the light carrot and raisin muffins at rank 5, to set it as the best answer for the search. Observe that the selected URL appears beneath the Best URLs heading.
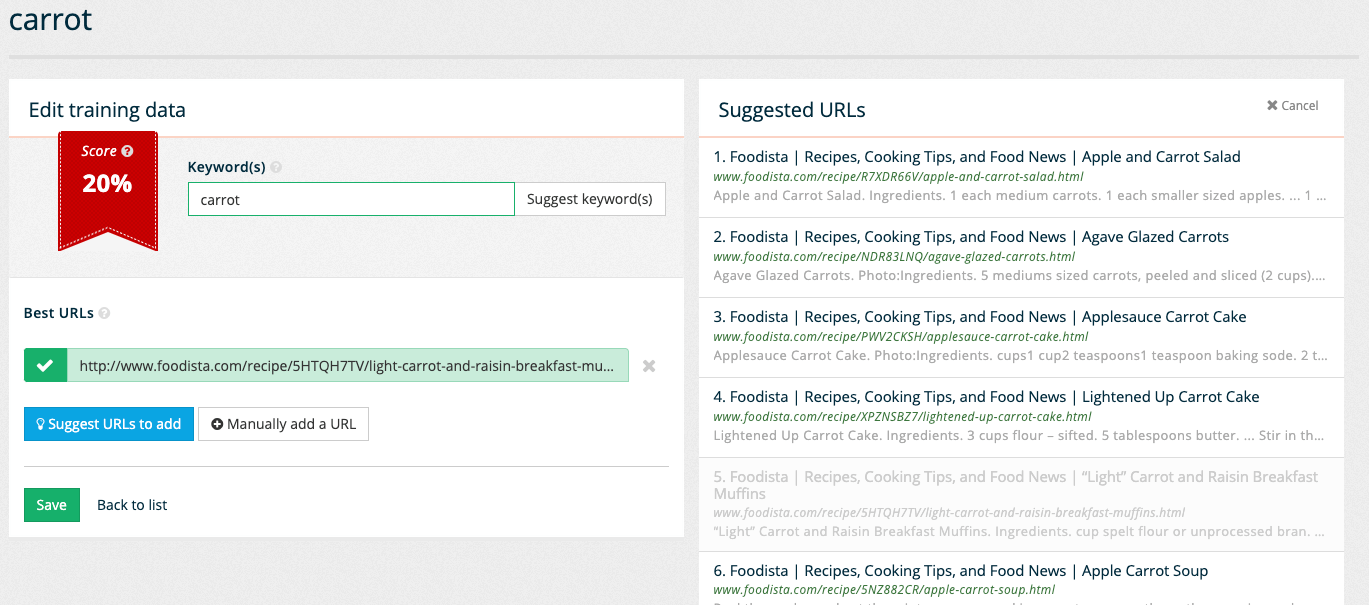
-
Save the sample search by clicking on the save button. The training data overview screen reloads showing the suggestion that was just saved.
-
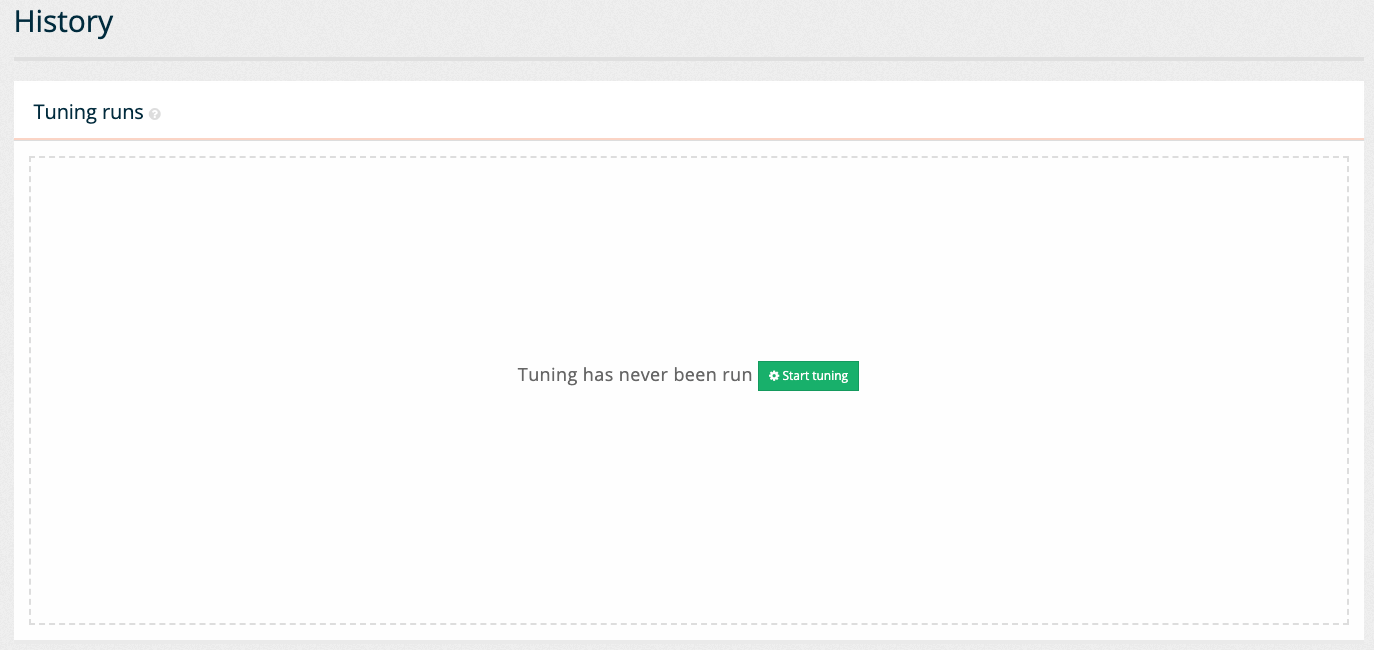
Run tuning by switching to the history screen. The history screen is accessed by selecting history from the left hand menu, or by clicking on the tuning runs button contained within the information message at the top of the screen.
-
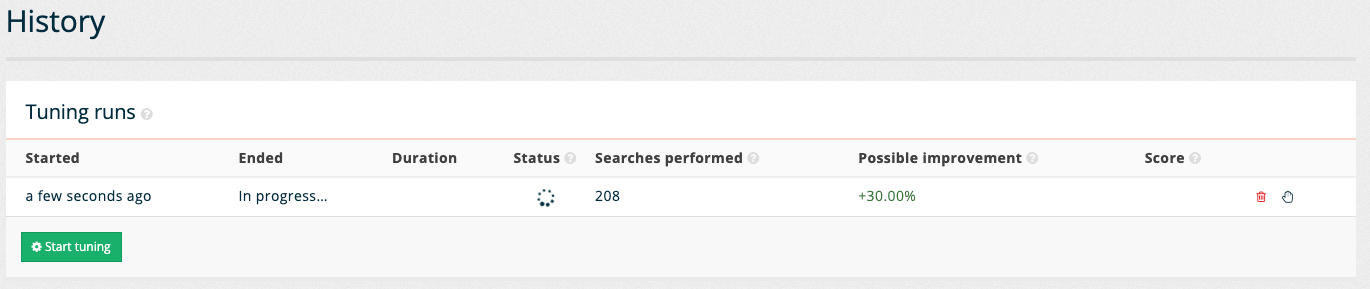
The history screen is empty because tuning has not been run on this results page. Start the tuning by clicking the start tuning button. The screen refreshes with a table showing the update status. The table shows the number of searches performed and possible improvement (and current score) for the optimal set of raking settings (based on the combinations that have been tried so far during this tuning run.
-
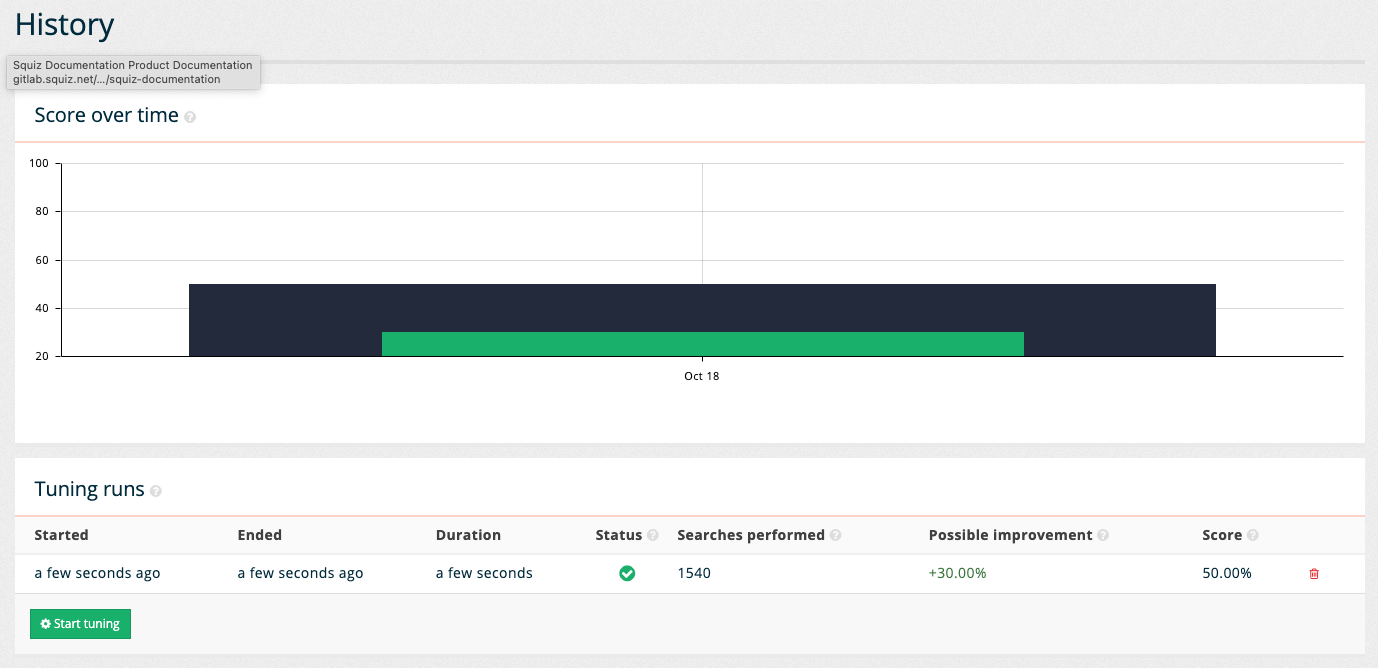
When the tuning run completes the display updates with a score over time chart that shows the current (in green) and optimized scores (in blue) over time.
-
Open the insights dashboard screen by clicking the Foodista dashboard item in the left hand menu and observe the tuning tile shows the current performance.
Tutorial: Apply tuning settings
-
To apply the optimal tuning settings return to the search dashboard, and manage the foodista search results page. Select view tuning results from the tuning panel.
-
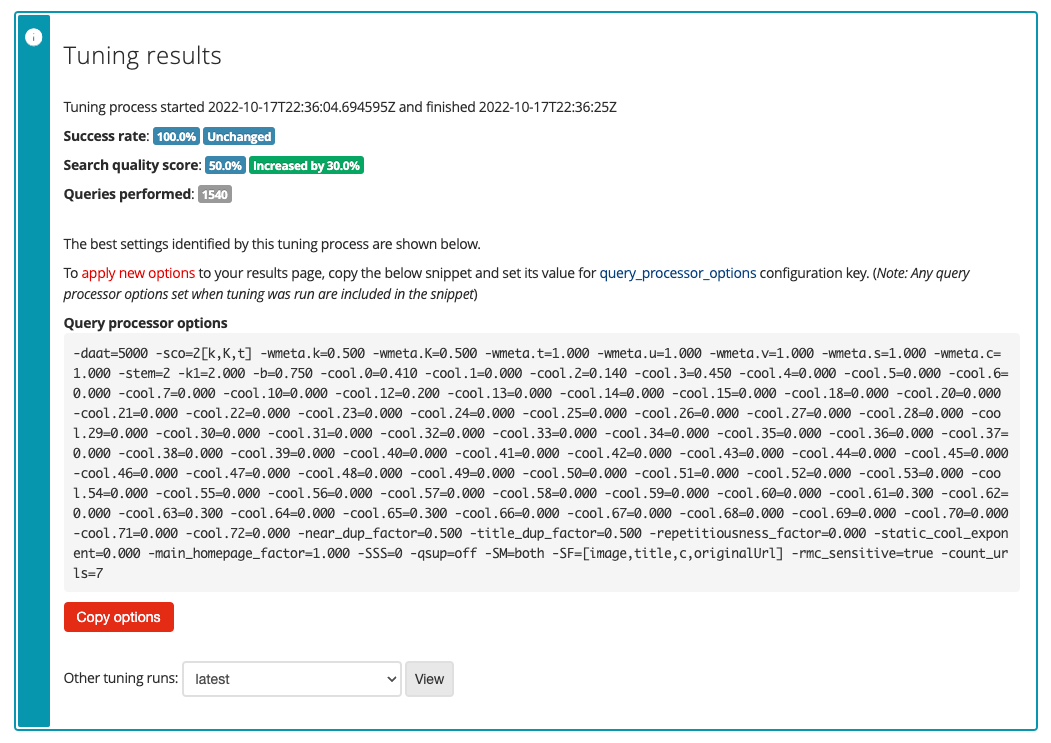
The tuning results screen will be displayed showing the optimal set of ranking settings found for the training data set.
-
To apply these tuning options click the copy options button. These options need to be added to the query processor options for the results page. Open the Foodista results page management screen and click the edit results page configuration item from the customize panel.
-
Click the add new button and add a query_processor_options key, adding the tuning settings to the
-stem=2item that is set by default, then click the save button (but don’t publish your changes yet).
-
Return to the results page management screen for the Foodista results page and run a search for carrot against the live version of the results page. This will run the search with current ranking settings.
-
Observe the results noting the first few results.
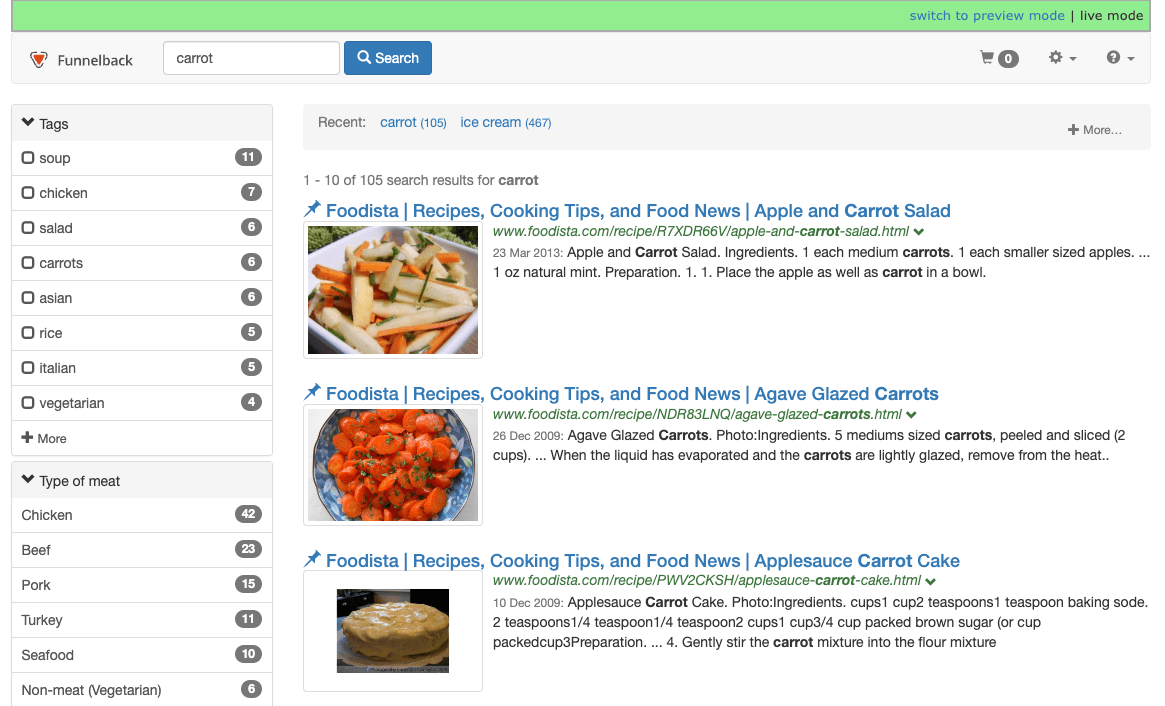
-
Click the switch to preview mode link on the green toolbar to run the same search but against the preview version of the results page. Alternatively, return to the foodista results page management screen and rerun the search for carrot, this time against the preview version of the results page. This will run the search with the tuned ranking settings.
-
Observe the results noting the first few results and that the URL you selected previously has moved up in the results.
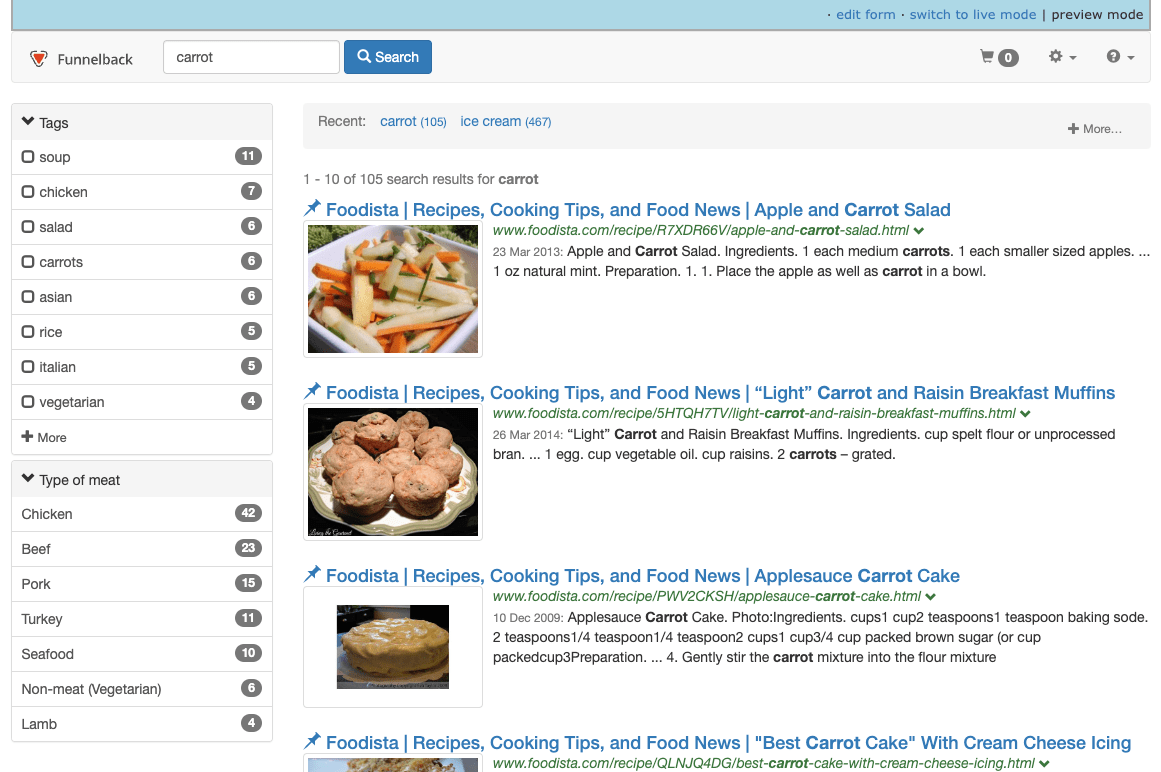
-
To make the ranking settings live return to foodista results page management screen and edit the results page configuration. Publish the
query_processor_optionssetting. Retest the live search to ensure that the settings have been applied successfully.
Setting ranking indicators
Funnelback has an extensive set of ranking parameters that influence how the ranking algorithm operates.
This allows for customization of the influence provided by 73 different ranking indicators.
| Automated tuning should be used (where possible) to set ranking influences as manually altering influences can result in fixing of a specific problem at the expense of the rest of the content. |
The main ranking indicators are:
-
Content: This is controlled by the
cool.0parameter and is used to indicate the influence provided by the document’s content score. -
On-site links: This is controlled by the
cool.1parameter and is used to indicate the influence provided by the links within the site. This considers the number and text of incoming links to the document from other pages within the same site. -
Off-site links: This is controlled by the
cool.2parameter and is used to indicate the influence provided by the links outside the site. This considers the number and text of incoming links to the document from external sites in the index. -
Length of URL: This is controlled by the
cool.3parameter and is used to indicate the influence provided by the length of the document’s URL. Shorter URLs generally indicate a more important page. -
External evidence: This is controlled by the
cool.4parameter and is used to indicate the influence provided via external evidence (see query independent evidence below). -
Recency: This is controlled by the
cool.5parameter and is used to indicate the influence provided by the age of the document. Newer documents are generally more important than older documents.
A full list of all the cooler ranking options is provided in the documentation link below.
Applying ranking options
Ranking options are applied in one of three ways:
-
Set as a default for the results page by adding the ranking option to the
query_processor_optionsparameter result spage configuration. -
Set at query time by adding the ranking option as a CGI parameter. This is a good method for testing but should be avoided in production unless the ranking factor needs to be dynamically set for each query, or set by a search form control such as a slider.
Many ranking options can be set simultaneously, with the ranking algorithm automatically normalizing the supplied ranking factors. For example:
query_processor_options=-stem=2 -cool.1=0.7 -cool.5=0.3 -cool.21=0.24Automated tuning is the recommended way of setting these ranking parameters as it uses an optimization process to determine the optimal set of factors. Manual tuning can result in an overall poorer end result as improving one particular search might impact negatively on a lot of other searches.
Tutorial: Manually set ranking parameters
-
Run a search against the foodista results page for sugar. Observe the order of search results.
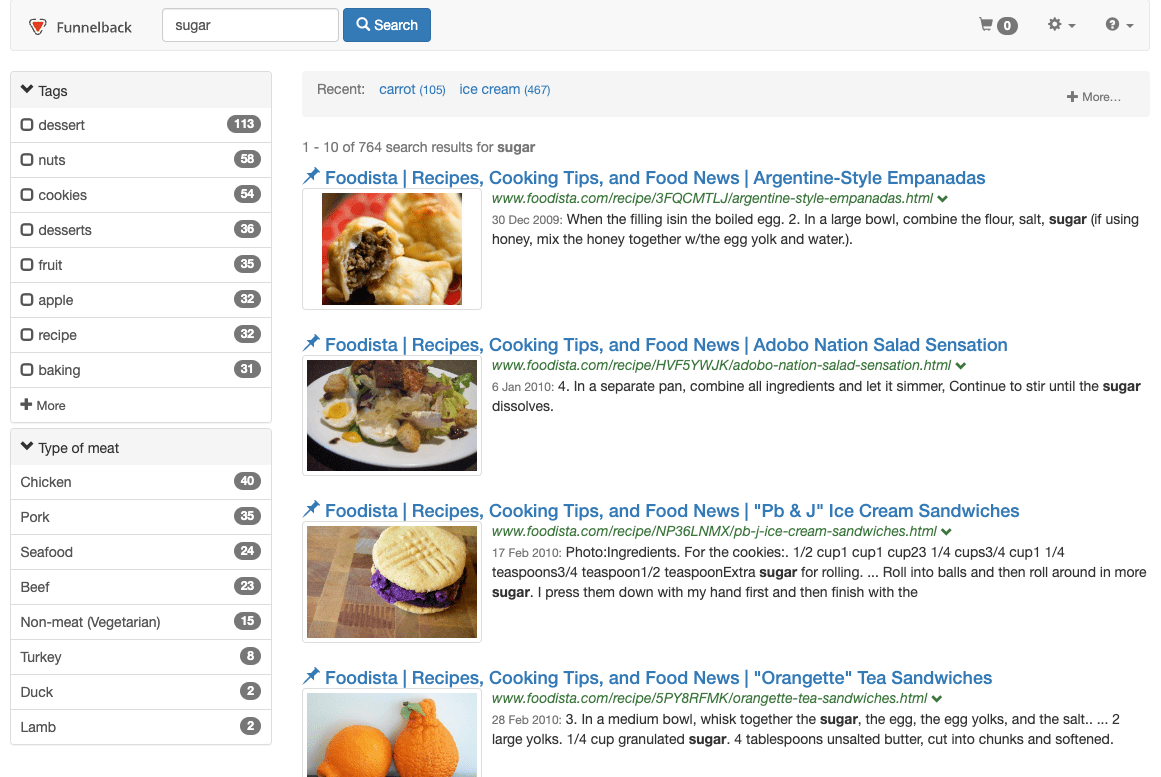
-
Provide maximum influence to document recency by setting
cool.5=1.0. This can be added as a CGI parameter, or in the query processor options of the results page configuration. Add&cool.5=1.0to the URL and observe the change in result ordering. Observe that despite the order changing to increase the influence of date, the results are not returned sorted by date (because there are still other factors that influence the ranking).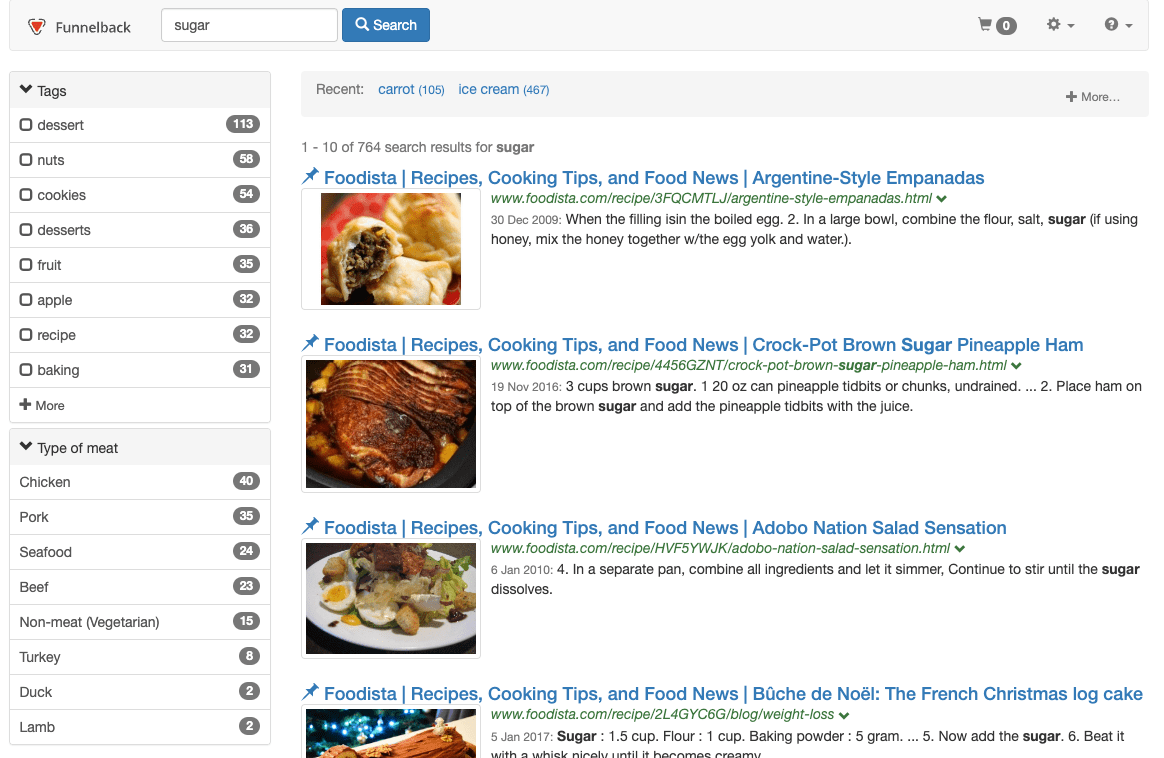
If your requirement was to just sort your results by date the best way of achieving this would be to switch from sorting by ranking to sorting by date. -
Open the results page management screen for the foodista results page.
-
Select edit results page configuration from the customize panel. Locate the query processor options setting and set
-cool.5=1.0to the query processor options, then save and publish the setting.this may already have been set by tuning so you might need to edit an existing value. 
-
Rerun the first search against the foodista results page and observe that the result ordering reflects the search that was run when recency was up-weighted. This is because the
cool.5setting has been set as a default for the results page. It can still be overridden by settingcool.5in the URL string, but will be set to 1.0 when it’s not specified elsewhere.
Data source component weighting
If you have more than one data source included in a search package it is often beneficial to weight the data sources differently. This can be for a number of reasons, the main ones being:
-
Some data sources are simply more important than others. For example, a university’s main website is likely to be more important than a department’s website.
-
Some data source types naturally rank better than others. For example, web data sources generally rank better than other data source types as there is a significant amount of additional ranking information that can be inferred from attributes such as the number of incoming links, the text used in these links and page titles. XML and database data sources generally have few attributes beyond the record content that can be used to assist with ranking.
Data source component weighting is controlled using the cool.21 parameter, and the relative data source weights are set in the search package configuration.
Tutorial: Apply data source relative weighting to a search package
-
From the search dashboard open the library search package management screen.
-
Click the edit search package configuration option from the settings panel.
-
In this example we’ll configure our library search package to push results from the Jane Austen data source up in the rankings, and push down the Shakespeare results. Add (and save, but don’t publish) two
meta.components.*.weightsettings for the two different data sources:Parameter key Data source Value meta.components.*.weightdefault~ds-austen0.9meta.components.*.weightdefault~ds-shakespeare0.3
Data sources have a default weight of 0.5. A value between 0.5 and 1.0 will add an up-weight to results from the data source. A value between 0.0 and 0.5 will result in a down-weight. You only need to add settings for the data sources that you wish to change from the default. .Run a search for queen and observe the search results order. This is the order that the search results return without any influence set for the weights you’ve just configured.
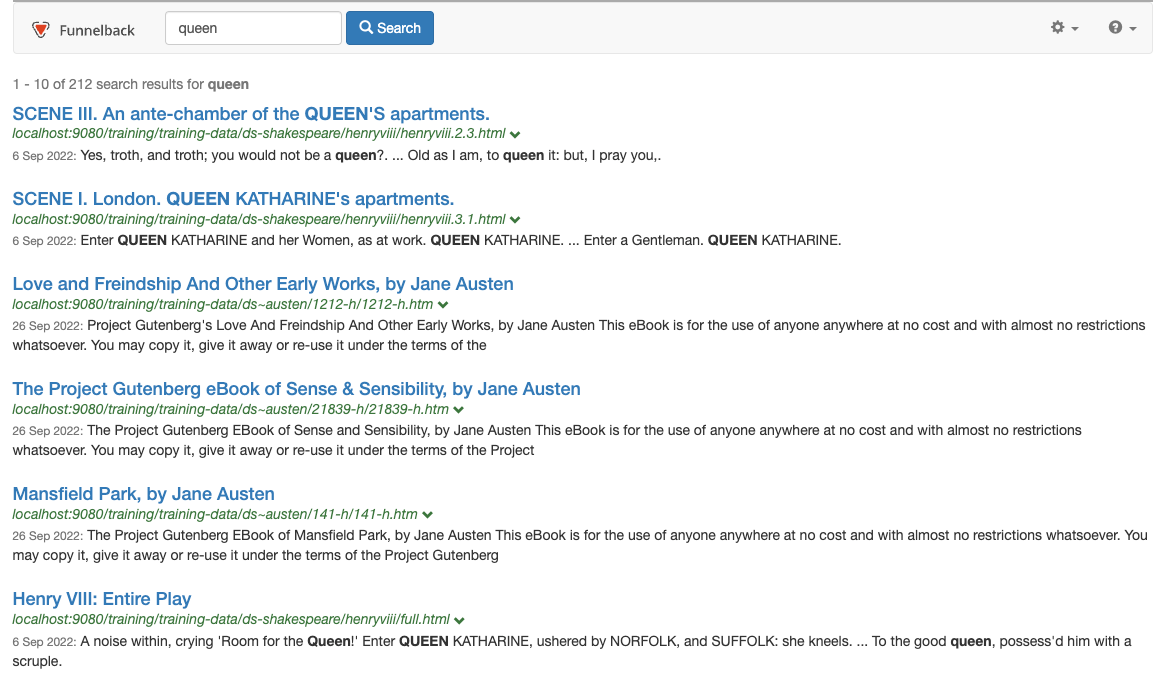
-
Edit the URL and add the following parameter:
&cool.21=1.0- this sets the maximum influence that can be provided by the data source relative weightings you’ve configured. Observe the effect on the search results order.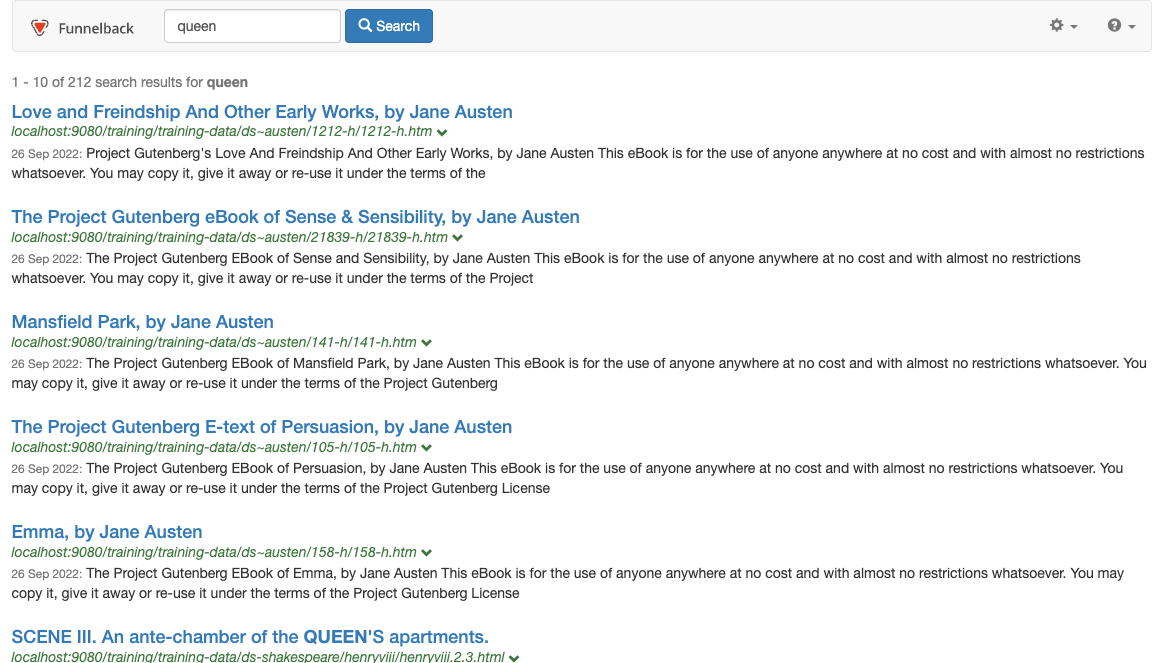
-
Adjust the influence by changing the value of the
cool.21parameter and observe the effect on the results. When you’ve found a value that you’re happy with you can apply this as the default for your results page by setting it in the results page configuration. -
Set the influence as a results page default by adding
-cool.21=0.9to thequery_processor_optionsin the results page configuration. -
Rerun the query, removing the
cool.21value from the URL and observe that your default setting is now applied.
Result diversification
There are a number of ranking options that are designed to increase the diversity of the result set. These options can be used to reduce the likelihood of result sets being flooded by results from the same website, data source, etc.
Same site suppression
Each website has a unique information profile and some sites naturally rank better than others. Search engine optimization (SEO) techniques assist with improving a website’s natural ranking.
Same site suppression can be used to down-weight consecutive results from the same website resulting in a more mixed/diverse set of search results.
Same site suppression is configured by setting the following query processor options:
-
SSS: controls the depth of comparison (in the URL) used to determining what a site is. This corresponds to the depth of the URL (or the number of sub-folders in a URL).
-
Range: 0-10
-
SSS=0: no suppression
-
SSS=2: default (site name + first level folder)
-
SSS=10: special meaning for big web applications.
-
-
SameSiteSuppressionExponent: Controls the down-weight penalty applied. Larger values result in greater down-weight.
-
Range: 0.0 - unlimited (default = 0.5)
-
Recommended value: between 0.2 and 0.7
-
-
SameSiteSuppressionOffset: Controls how many documents are displayed beyond the first document from the same site before any down-weight is applied.
-
Range: 0-1000 (default = 0)
-
-
sss_defeat_pattern: URLs matching the simple string pattern are excluded from same site suppression.
Same meta suppression
Down-weights subsequent results that contain the same value in a specified metadata field. Same meta suppression is controlled by the following ranking options:
-
same_meta_suppression: Controls the down-weight penalty applied for consecutive documents that have the same metadata field value.
-
Range: 0.0-1.0 (default = 0.0)
-
-
meta_suppression_field: Controls the metadata field used for the comparison. Note: only a single metadata field can be specified.
Same collection (data source) suppression
Down-weights subsequent results that come from the same data source. This provides similar functionality to the data source relative weighting above and could be used in conjunction with it to provide an increased influence. Same collection suppression is controlled by the following ranking options:
-
same_collection_suppression: Controls the down-weight penalty applied for consecutive documents that are sourced from the same data source.
-
Range: 0.0-1.0 (default = 0.0)
-
Same title suppression
Down-weights subsequent results that contain the same title. Same title suppression is controlled by the following ranking options:
-
title_dup_factor: Controls the down-weight penalty applied for consecutive documents that have the same title value.
-
Range: 0.0-1.0 (default = 0.5). Setting to
1.0disables same title suppression.
-
Near-duplicate (very similar) title suppression
Down-weights subsequent results that contain a near-duplicate (very similar) title. Near-duplicate title suppression is controlled by the following ranking options:
-
near_dup_factor: Controls the down-weight penalty applied for consecutive documents that have a near-duplicate title value.
-
Range: 0.0-1.0 (default = 0.5). Setting to
1.0disables near-duplicate title suppression.
-
Tutorial: Same site suppression
-
Run a search against the simpsons results page for homer. Observe the order of the search results noting that the results are spread quite well with consecutive results coming from different folders. Funnelback uses same site suppression to achieve this and the default setting (
SSS=2, which corresponds to hostname and first folder) is applied to mix up the results a bit.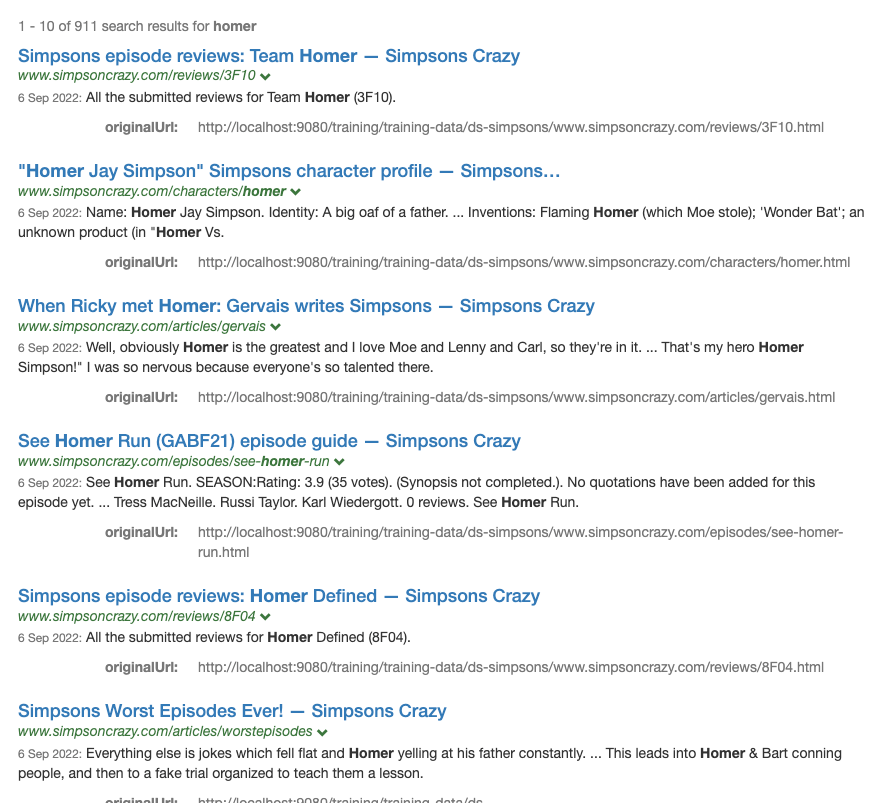
-
Turn off same site suppression by adding
&SSS=0to the URL observing the effect on the search result ordering.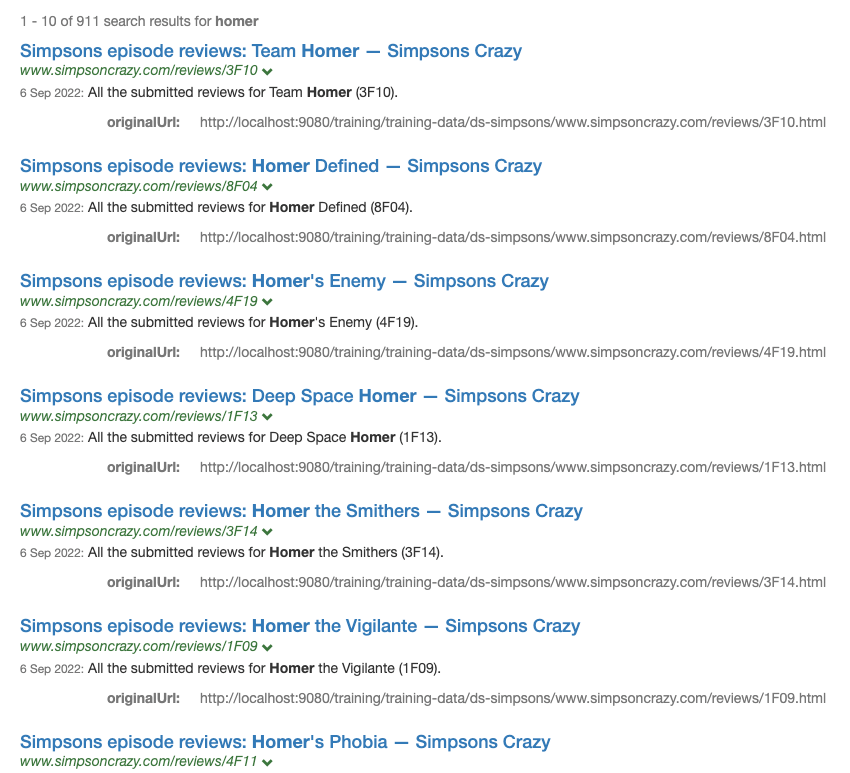
-
Remove the
SSS=0parameter from the URL to re-enable the default suppression and addSameSiteSuppressionOffset=2to change the suppression behaviour so that it kicks in after a few results. This causes several reviews items to remain unaffected by any penalty that is a result of being from the same section as the previous result.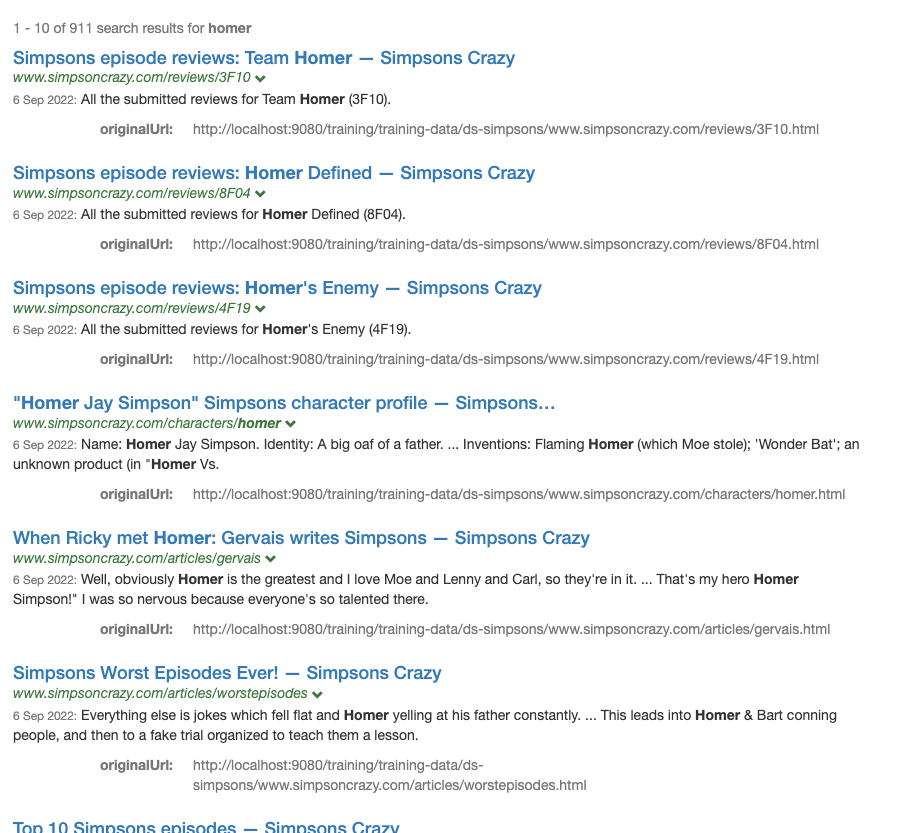
Result collapsing
While not a ranking option, result collapsing can be used to effectively diversify the result set by grouping similar result items together into a single result.
Results are considered to be similar if:
-
They share near-identical content
-
They have identical values in one or a set of metadata fields.
Result collapsing requires configuration that affects both the indexing and query time behaviour of Funnelback.
Tutorial: Configure result collapsing
-
Log in to the search dashboard and change to the Nobel Prize winners data source
-
Configure three keys to collapse results on - year of prize, prize name and a combination of prize name and country. Edit the data source configuration settings then select the indexer item from the left hand menu.
-
Update the result collapsing fields to add collapsing on year, prize name and prize name+country.
[$],[H],[year],[prizeName],[prizeName,country]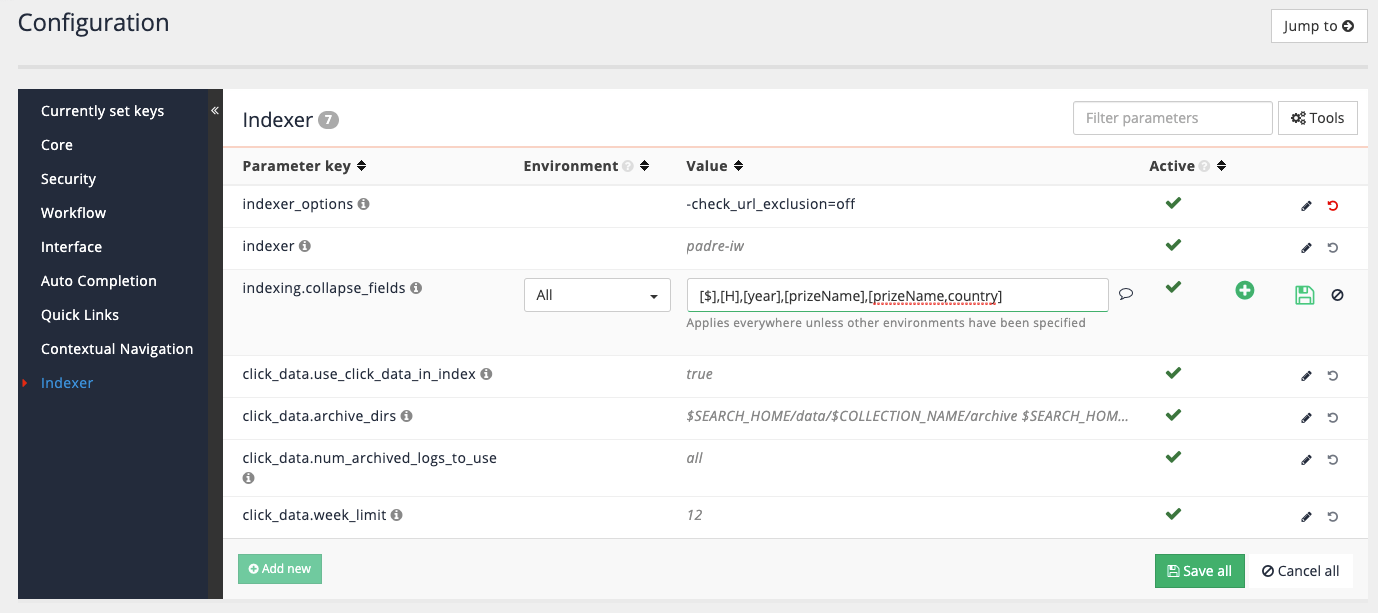
$is a special value that collapses on the document content (can be useful for collapsing different versions or duplicates of the same document).Hcontains an MD5 sum of the document content which is used for collapsing of duplicate content. -
Rebuild the index by selecting rebuild the live index from the advanced update options.
-
Ensure the template is configured to displayed collapsed results. Switch to the Nobel Prize winners search results page, then edit the results page template. Locate the section of the results template where each result is printed and add the following code just below the closing
</ul>tag for each result (approx line 500). This checks to see if the result element contains any collapsed results and prints a message.<#if s.result.collapsed??> <div class="search-collapsed"><small><span class="glyphicon glyphicon-expand text-muted"></span> <@fb.Collapsed /></small></div> </#if>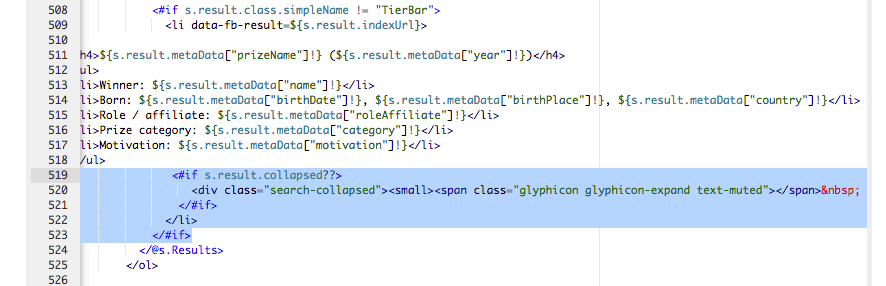
-
Test the result collapsing by running a query for prize and adding the following to the URL:
&collapsing=on&collapsing_sig=[year]. (http://localhost:9080/s/search.html?collection=default\~sp-nobel-prize&profile=nobel-prize-winners-search&query=prize&collapsing=on&collapsing_sig=%5Byear%5D) Observe that results contain an additional link indicating the number of very similar results and the result summary includes a message indicating that collapsed results are included.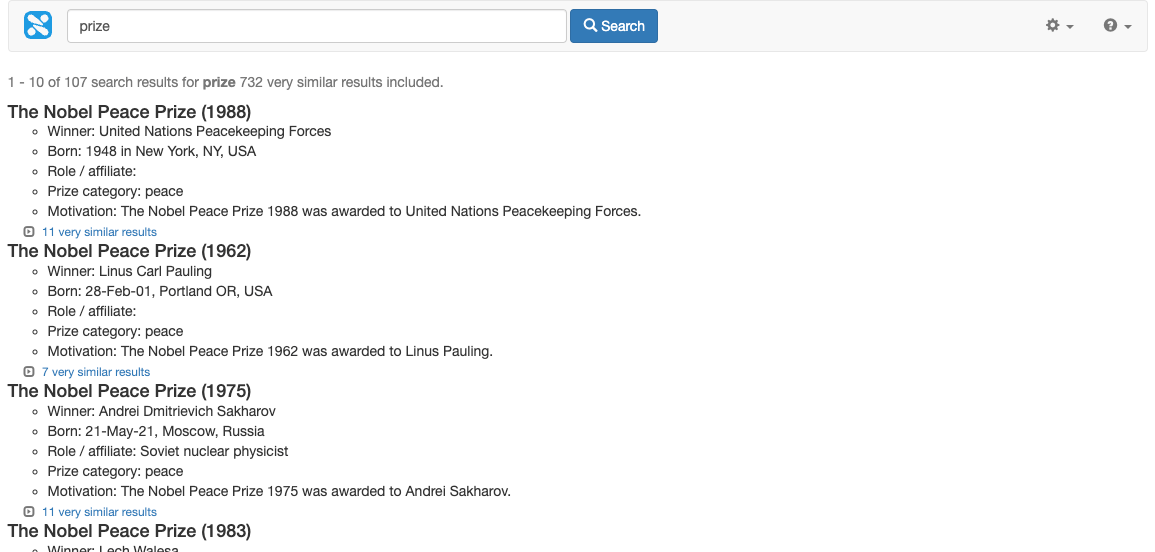
-
Clicking on this link will return all the similar results in a single page.

-
Return to the previous search listing by pressing the back button and inspect the JSON (or XML) view of the search observing that the result summary contains a collapsed count and that each result item contains a collapsed field. This collapsed field indicates the number of matching items and the key on which the match was performed and can also include some matching results with metadata. Observe that there is a results sub-item, and it’s currently empty:

-
Return some results into the collapsed sub-item by adding the following to the URL:
&collapsing_num_ranks=3&collapsing_SF=[prizeName,name](http://localhost:9080/s/search.json?collection=training\~sp-nobel-prize&profile=nobel-prize-winners-search&query=prize&collapsing=on&collapsing_sig=%5Byear%5D&collapsing_num_ranks=3&collapsing_SF=%5BprizeName)The first option,
collapsing_num_ranks=3tells Funnelback to return 3 collapsed item results along with the main result. These can be presented in the result template as sub-result items. The second option,collapsing_SF=[prizeName,name]controls which metadata fields are returned in the collapsed result items.
-
Modify the search results template to display these collapsed results as a preview below the main result. Edit your search result template and locate the following block of code:
<#if s.result.collapsed??> <div class="search-collapsed"><small><span class="glyphicon glyphicon-expand text-muted"></span> <@fb.Collapsed /></small></div> </#if>and replace it with the following:
<#if s.result.collapsed??> <div style="margin-left:2em; border:1px dashed black; padding:0.5em;"> <h5>Preview of very similar results</h5> <#list s.result.collapsed.results as r> (1) <p><a href="${r.indexUrl}">${r.listMetadata["prizeName"]?first!} (${r.listMetadata["year"]?first!}): ${r.listMetadata["name"]?first!}</a></p> </#list> <div class="search-collapsed"><small><span class="glyphicon glyphicon-expand text-muted"></span> <@fb.Collapsed /></small></div> </div> </#if>1 Iterates over the results sub-item and displays a link containing the metadata values for each item. -
Access the search results, this time viewing the HTML version of the search results and observe that the items returned in the JSON are now displayed below the search results. (http://localhost:9080/s/search.html?collection=training\~sp-nobel-prize&profile=nobel-prize-winners-search&query=prize&collapsing=on&collapsing_sig=%5BprizeName%5D&collapsing_num_ranks=3&collapsing_SF=%5BprizeName)
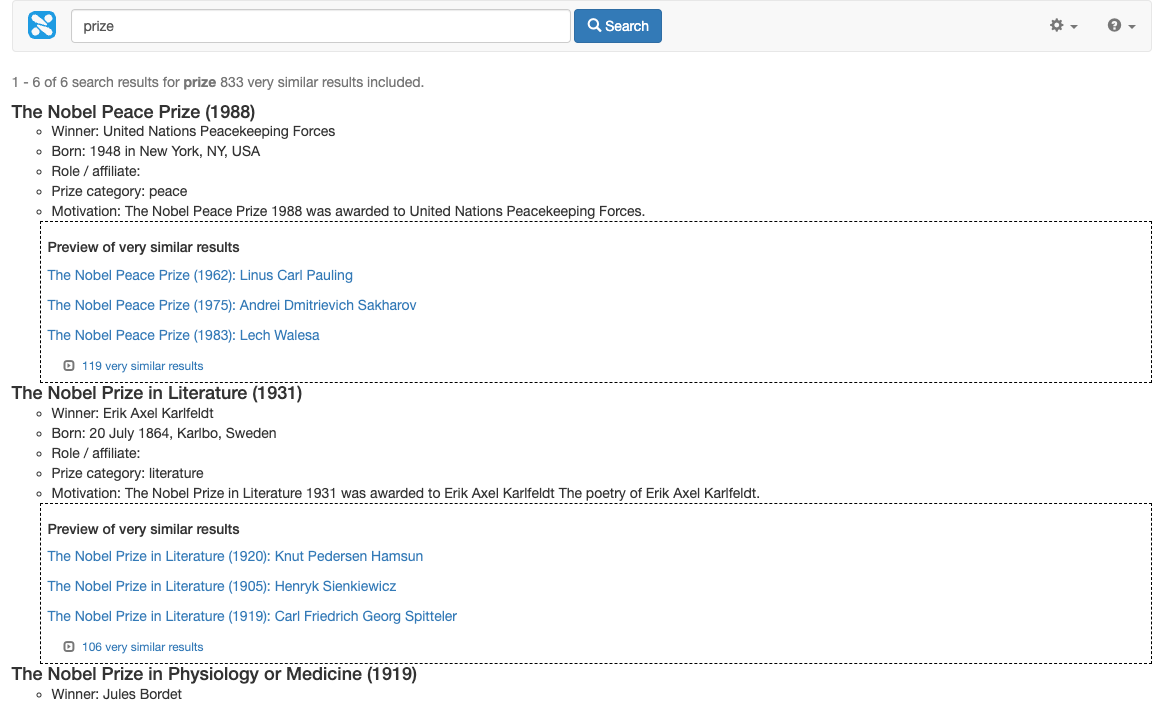
-
Return to the initial search collapsing on year (http://localhost:9080/s/search.html?collection=training\~sp-nobel-prize&profile=nobel-prize-winners-search&query=prize&collapsing=on&collapsing_sig=%5Byear%5D) and change the collapsing_sig parameter to collapse on
prizeName: (http://localhost:9080/s/search.html?collection=training\~sp-nobel-prize&profile=nobel-prize-winners-search&query=prize&collapsing=on&collapsing_sig=%5BprizeName%5D). Observe that the results are now collapsed by prize name.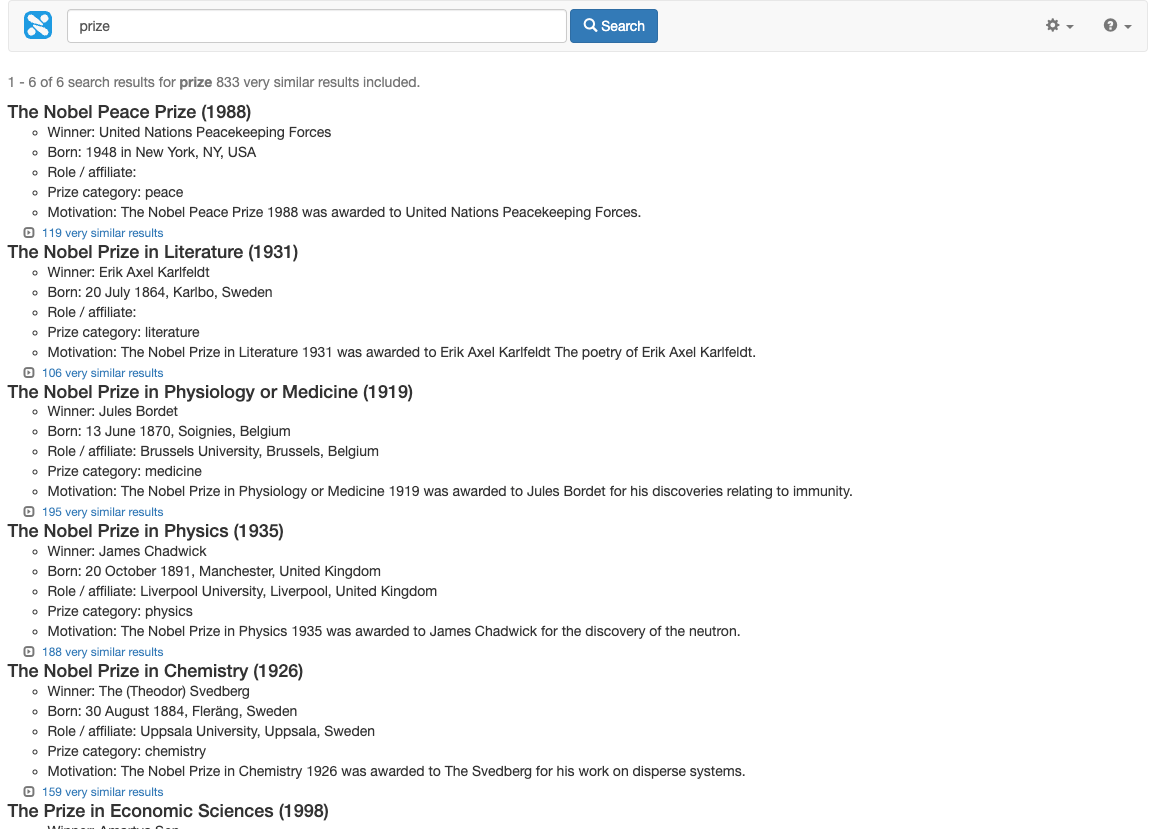
-
Finally, change the collapsing signature to collapse on
[prizeName,country](http://localhost:9080/s/search.html?collection=training\~sp-nobel-prize&profile=nobel-prize-winners-search&query=prize&collapsing=on&collapsing_sig=%5BprizeName,country%5D). This time the results are collapsed grouping all the results for a particular prize category won by a specific country. For example, result item 1 below groups all the results where the Nobel Peace Prize was won by someone from the USA.
-
Click on the 24 very similar results link and confirm that the 25 results returned are all for the Nobel Peace Prize and that each recipient was born in the USA.
There are 25 results because this search returns the parent result in addition to the 24 results that were grouped under the parent. 
-
The values for
collapsing,collapsing_sig,collapsing_SFandcollapsing_num_rankscan be set as defaults in the same way as other display and ranking options, in the results page configuration.
Metadata weighting
It is often desirable to up- (or down-) weight a search result when search keywords appear in specified metadata fields.
The following ranking options can be used to apply metadata weighting:
-
sco=2: Setting the-sco=2ranking option allows specification of the metadata fields that will be considered as part of the ranking algorithm. By default, link text, clicked queries and titles are included. The list of metadata fields to use with sco2 is defined within square brackets when setting the value. For example,-sco=2[k,K,t,customField1,customField2]tells Funnelback to apply scoring to the default fields as well ascustomField1andcustomField2. Default:-sco=2[k,K,T] -
wmeta: Once the scoring mode to is set to 2, any defined fields can have individual weightings applied. Each defined value can have a wmeta value defined specifying the weighting to apply to the metadata field. The weighting is a value between 0.0 and 1.0. A weighting of 0.5 is the default and a value >0.5 will apply an upweight. A value <0.5 will apply a downweight. For example,-wmeta.t=0.6applies a slight upweighting to the t metadata field while-wmeta.customField1=0.2applies a strong downweighting tocustomField1.
Tutorial: Custom metadata weighting
-
Switch to the foodista results page and perform a search for pork (http://localhost:9080/s/search.html?collection=training~sp-foodista&query=pork).
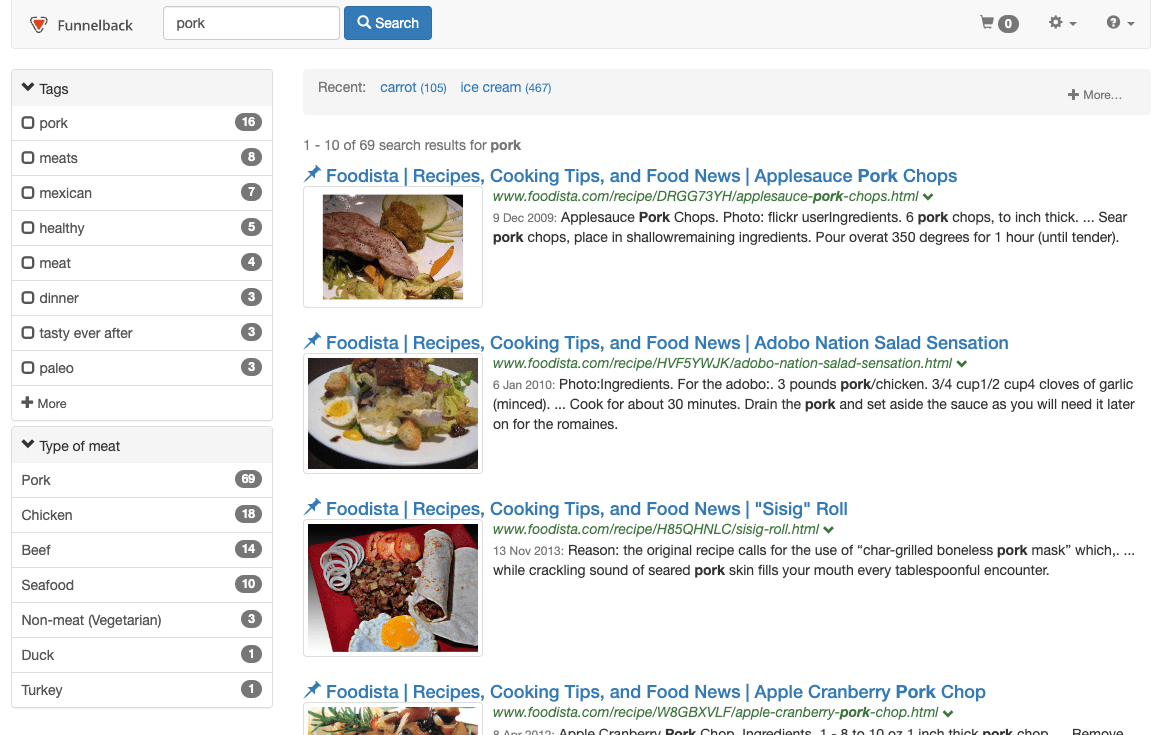
-
Change the settings so that the maximum up-weight is provided if the search query terms appear within the tags field. Remove the influence provided by the title metadata. Set the query processor options to the following (other query processor options may have been set for previous exercises so remove them and add the following):
-stem=2 -SF=[image,title,c,originalUrl] -sco=2[k,K,t,tags] -wmeta.tags=1.0 -wmeta.t=0.0or as CGI parameters (http://localhost:9080/s/search.html?collection=training~sp-foodista&query=pork&sco=2%5bt%2Ck%2CK%2Ctags%5d&wmeta.tags=1.0&wmeta.t=0.0). Observe the effect on the ranking of the results
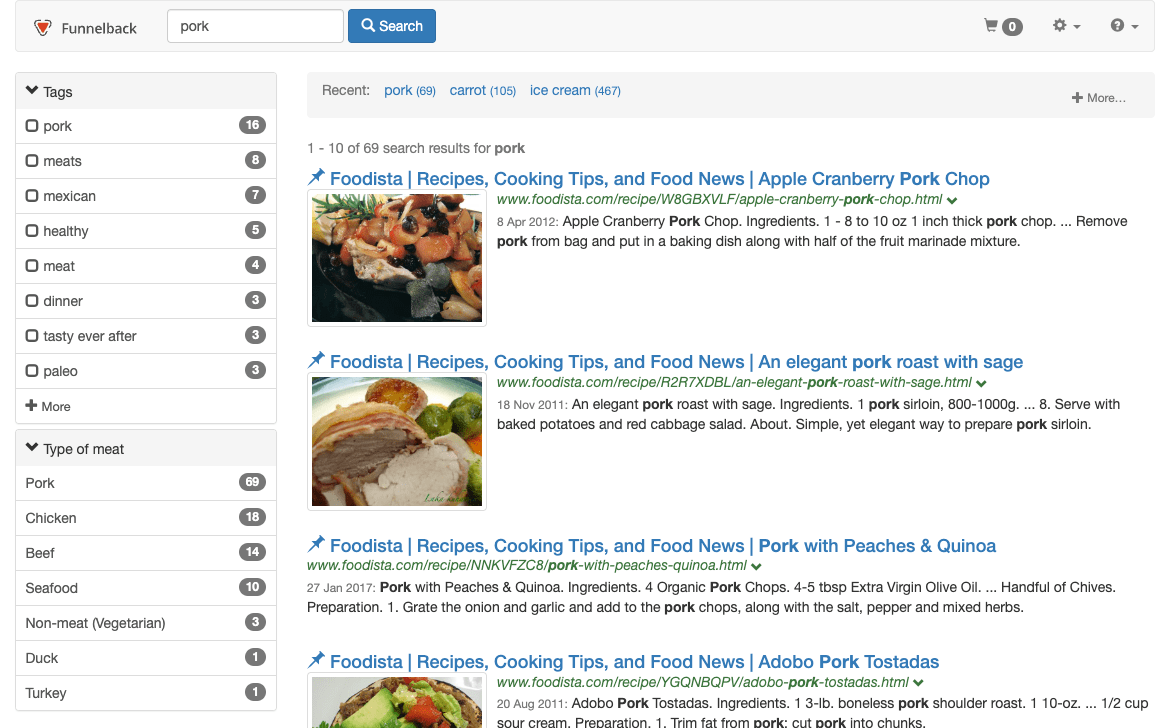
The -stemand-SFoptions are needed for other things and don’t related to the ranking changes you are making.
Query independent evidence
Query independent evidence (QIE) allows certain pages or groups of pages within a website (based on a regular expression match to the document’s URL, or if it’s returned when a specific query is run) to be up-weighted or down-weighted without any consideration of the query being run.
This can be used for some of the following scenarios:
-
Provide up-weight to globally important pages, down-weight the home page.
-
Weighting different file formats differently (for example, up-weight PDF documents).
-
Apply up or down weighting to specific websites.
Query independent evidence is applied in two steps:
-
Defining the relative weights of items to up-weight or down-weight by defining URL patterns in the
qie.cfgconfiguration file, or queries in thequery-qie.cfgconfiguration file. This generates an extra index file that records the relative weights of documents. -
Applying an influence within the ranking algorithm to query independent evidence by setting a weighting for
cool.4.The weighting forcool.4can be adjusted dynamically (for example, to disable it via a CGI parameter by setting&cool.4=0.0) or per profile.
Tutorial: Query independent evidence
-
Log in to the search dashboard and switch to the simpsons - website data source.
-
Click the manage data source configuration files item from the settings panel and create a
qie.cfgfile -
Add the following URL weightings to the
qie.cfgand then save the file: 0.25 provides a moderate down-weight, while 1.0 is the maximum up-weight that can be provided via QIE. Items default to having a weight of 0.5.# down-weight reviews and upweight episodes 0.25 www.simpsoncrazy.com/reviews/ 1.0 www.simpsoncrazy.com/episodes/ -
Re-index the data source ( From the update panel: .
-
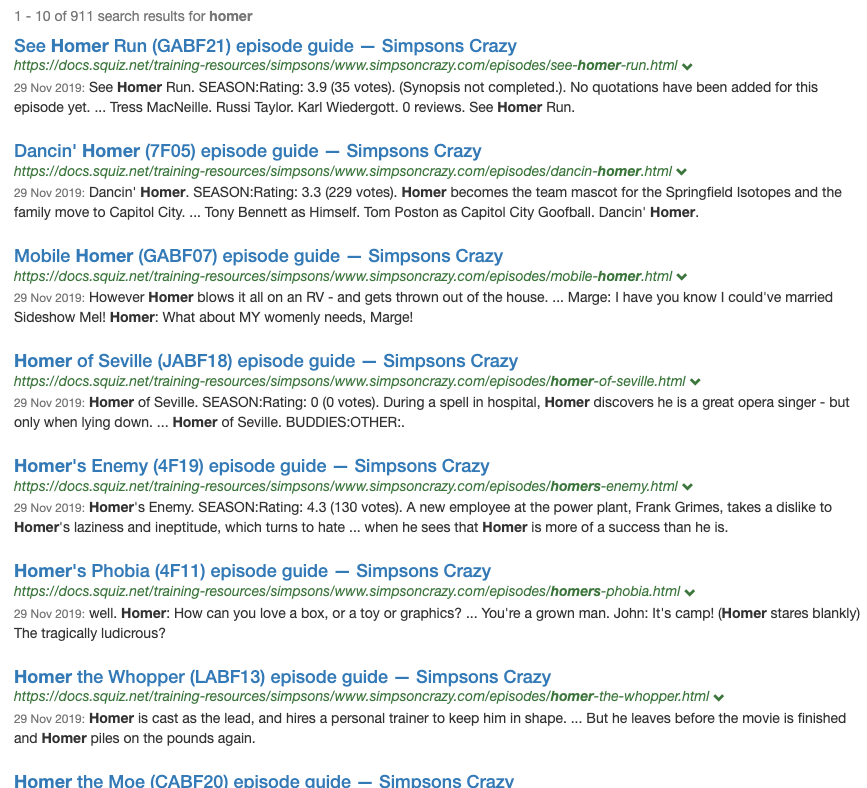
Switch to the simpsons results page, then run a query for homer adding
cool.4=0and thencool.4=1.0to the URL to observe the effect of QIE when it has no influence and when it has the maximum influence. Applying the maximum influence from QIE pushes episode pages to the top of the results (and this is despite the default same site suppression being applied).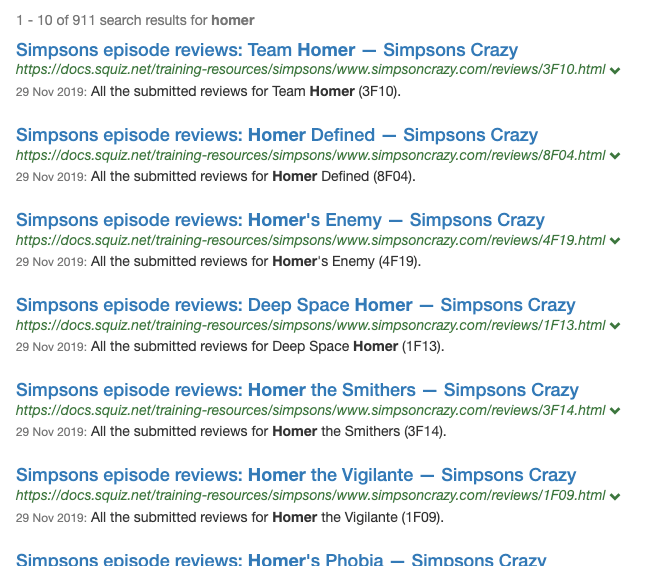
-
Like other ranking settings you can set this in the results page configuration once you have found an appropriate influence to apply to your QIE.