Data sources
A data source contains configuration and indexes relating to a set of information resources such as web pages, documents or social media posts.
Each data source implements a gatherer (or connector) that is responsible for connecting to the content repository and gathering the information to include in the index.
See also: Choosing a data source
| A data source is similar to a non-meta collection in older versions of Funnelback. |
Data source types
Funnelback includes a number of data source types:
-
Web content gathered using a web crawler. Includes websites and other resources made available via http.
-
Modern Campus Catalog (Acalog)
Course catalog data stored within Modern Campus Catalog / Acalog can be indexed using the CSV export option, available within the system’s admin interface.
-
Information gathered using a custom gatherer. Commonly used to index content obtained via APIs or an SDK. The custom gatherer is implemented via a Funnelback plugin.
-
Information gathered from the result of running an SQL query against a compatible database.
-
Information gathered from the result of running a directory (for example, LDAP) query against a compatible directory.
-
Facebook content gathered using Facebook’s APIs.
-
Documents gathered from a fileshare.
-
Flickr content gathered using Flickr’s APIs.
-
Instagram content gathered using Instagram’s APIs using a custom data source and the Instagram gatherer plugin
-
Documents gathered from an SFTP server.
-
Twitter content gathered using Twitter’s APIs.
-
Vimeo content gathered using Vimeo’s APIs.
-
YouTube content gathered using YouTube’s APIs.
-
An index-only data source that allows the indexing of content that is added via an API. An index only data source does not include gathering logic.
Populating a data source
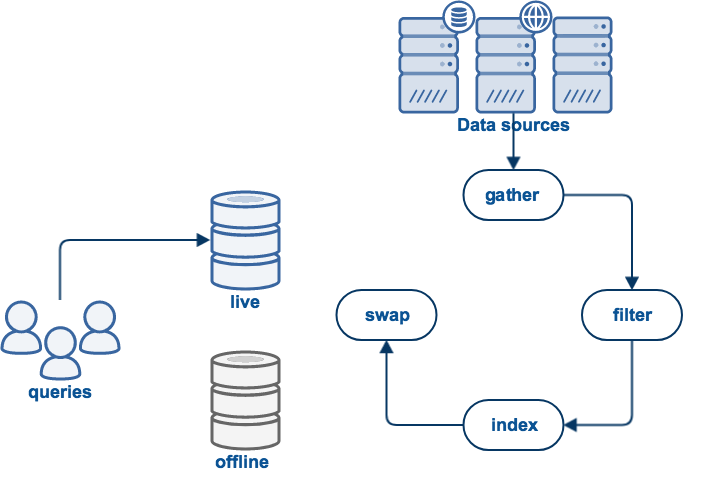
A (non-push) data source update follows the following high level steps:
-
The data is gathered. For example, if it is a web data source the web sites will be crawled to download all HTML files and other documents.
-
All "binary" documents are filtered to extract plain text. For example, PDF files will be processed to extract the text.
-
The documents will be indexed: word lists and other information will be processed into Funnelback indexes. The index is then used to answer user queries.
All of this work occurs in an offline area to prevent disrupting the current live view which is being used for query processing. If the update process completed successfully, the live and offline views will be swapped, making the new indexes available for querying.
See: Gather and index update flows for detailed information on all the update steps.
Manage a data source
The data source management screen is accessed in the following way:
-
From the search dashboard home page locate your search package in the main listing.
-
Click on the data sources tab for the search package.
-
Click on the name of the data source that you wish to edit, or select configuration from the settings menu.
For details on how to manage Funnelback data sources, see the following: