Defining the search results that are included in a results page
Define scoping configuration for your results page to enable users to search within a defined subset of pages within your search index.
When defining a results page you should think about what the purpose of the results page is, and scope the index appropriately. This allows you to provide more relevant results to your users by excluding parts of the search index that are not relevant to the search.
How you scope the results page will depend on the purpose of the results page. For example:
If the results page is the global site search, you may want to search across everything in the index (in this case you don’t apply any scoping), of if you are defining a publications search then it makes sense to scope the search so that it can only ever return results from your publications section.
There are various ways that you can define the set of pages covered by your results page:
-
Restricting the results to items from one or more specific data sources.
-
Restricting the results to items that match sets of items based on the URL.
-
Restricting the results to items that match sets of items based on a metadata constraint.
-
Restricting the results to the set items that are returned by a pre-defined search query.
| Once you define the scope on your results page, any searches that a user input will search within this set of items. |
Scoping search results to a one or more data sources
Use this option if you have multiple data sources in your index and want to create a results page that includes all results from one or more of these data sources.
The parent search package for your results page defines a set of data sources that make up the search index for your search. When you configure your results page you can scope the set of results to only be returned from specific data sources using setting the clive parameter in the query processor options of the results page configuration.
This option can be set multiple times within your query processor options and should be set for each data source that you wish to include.
Example: restrict results to the example~intranet and example~staff data sources
Using a query processor option, set in the results page options, add -clive parameters to your query processor options for each data source:
Query processor options |
|
Tutorial: Define a scope for a results page
When a new results page is created it has the same content as the parent search package.
Results pages are commonly used to provide a search across a sub-set of content within the search package. To achieve this the results page should be configured to apply a default scope.
In this exercise the Shakespeare search results page will be scoped so that only URLs from the Shakespeare website are returned when the running searches using the Shakespeare search results page.
The Shakespeare search results page is selected by passing a profile parameter set to the results page ID (shakespeare-search) in the search query.
-
Log in to the search dashboard where you are doing your training.
See: Training - search dashboard access information if you’re not sure how to access the training. Ignore this step if you’re treating this as a non-interactive tutorial. -
Locate the library search package.
-
Create another results page, but this time call the results page Shakespeare search.
-
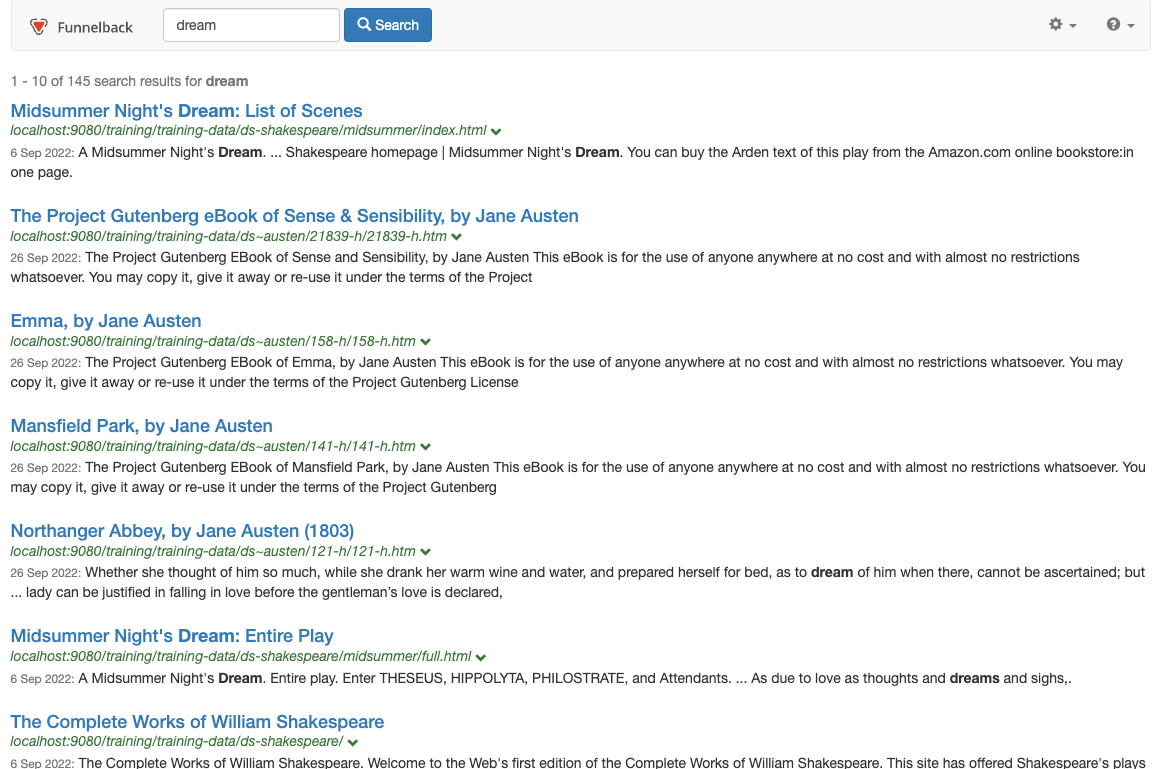
Run a search for dream ensuring the preview option is selected and observe that pages from both the Shakespeare and Austen sites are returned.

-
Select edit results page configuration from the customize section. The index can be scoped by setting an additional query processor option.
Query processor options are settings that can are applied dynamically to a Funnelback search when a query is made to the search index. The options can control display, ranking and scoping of the search results and can be varied for each query that is run. -
Add a query processor option to scope the results page - various options can be used to scope the results page including
scope,xscope,gscope1andclive. Thecliveparameter is a special scoping parameter that can be applied to results page to restrict the results to only include pages from a specified data source or set of data sources. The clive parameter takes a list of data source IDs to include in the scoped set of data. Add acliveparameter to scope the results page to pages from the training~ds-shakespeare data source then click the save button, (but do not publish) the file. You can find the data source ID in the information panel at the top of the results page management screen.-clive=training~ds-shakespeare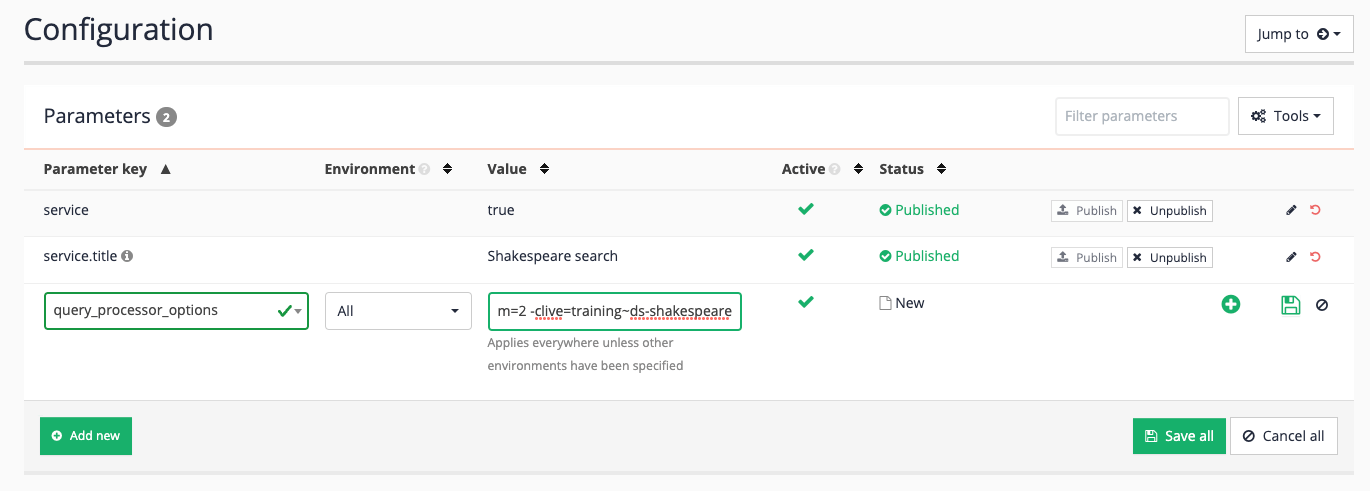
-
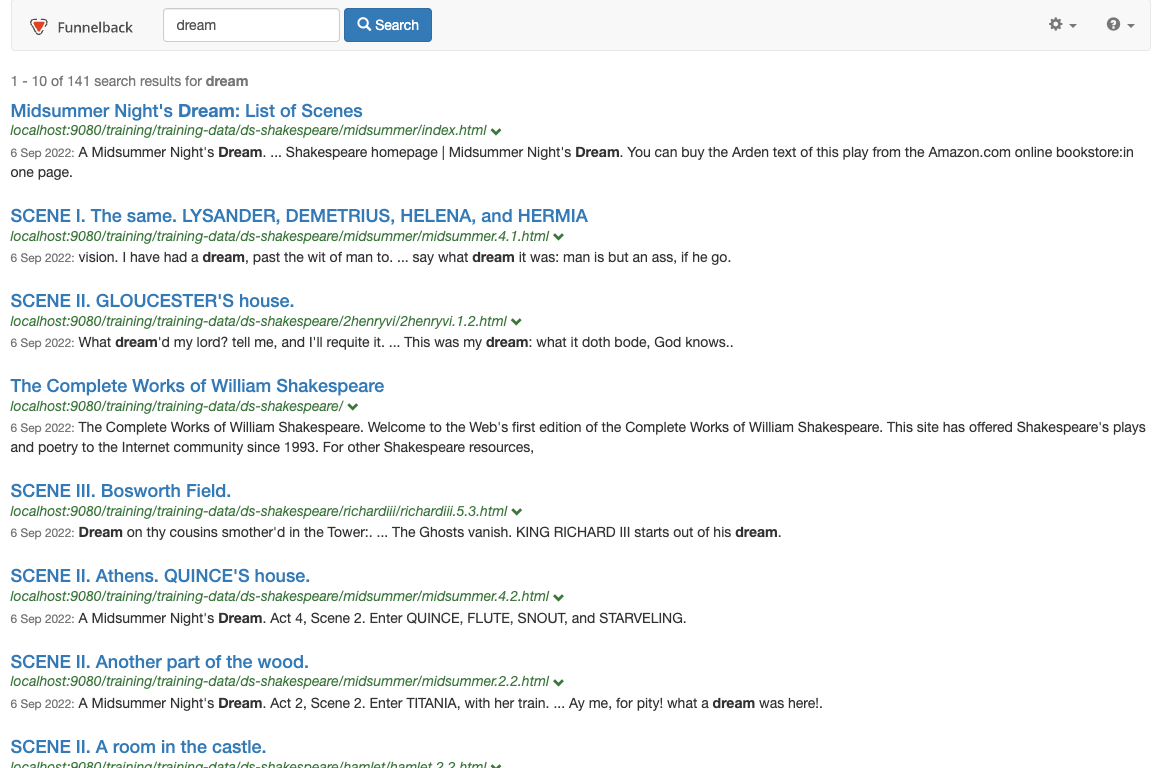
Rerun the search for dream against the preview version of the Shakespeare search results page and observe that the results are now restricted to only pages from the Shakespeare site.

-
Rerun the search for dream against the live version of the Shakespeare search results page. Observe that pages are returned from both sites - this is because the query processor options must be published for the changes to take effect on the live version of the results page.
-
Edit results page configuration again, and publish the query processor options to make the setting affect the live version of the results page.
-
Rerun the search for dream against the Shakespeare search results page. Observe that pages are now restricted to Shakespeare site pages.
Scoping search results to items that have URLs that match a pattern
Use this option if you want to scope the results page to only include pages that can be identified based on their URL. For example, http://example.com/publications/*
Scoping using generalized scopes (gscopes)
| The gscopes setup must be configured on each data source. |
Generalized scopes (gscopes) can be used to tag URLs within the data sources based on a match to the URL. When using gscopes to scope your results page you need to define a gscope ID which you will configure in each data source. This gscope ID will specify what subset of pages from the data source are tagged with the ID. You then configure your results page to use this gscope and this determines what set of pages are searched across when you access your results page.
-
Define the gscope on each data source that contains matching items. For each data source:
-
Create or edit the
gscopes.cfgand define a specific gscope. The ID must be the same in each of the data sources, but can have varying URL patterns. You can define multiple URL patterns for a single gscope in each data source. -
Run an advanced update of the data source (to apply the gscopes).
-
-
Configure your results page to scope the index using the gscope you configured in step 1.
-
Edit your results page configuration and add/edit the query processor options to include a
-gscope1parameter set to the gscope you defined in step 1.
-
Example: restrict results to the publications and pubs folders
In this example we have two data sources. We would like to search over publications. In data source 1, publications are stored within the path http://example.com/assets/publications/. In data source 1, publications are stored within the paths http://example.co.uk/pubs/ and http://archive.example.co.uk/releases/publications/
-
Create a
gscopes.cfgon data source 1 and define a gscope calledpublications:gscopes.cfgpublications example\.com/assets/publications/ -
Create a
gscopes.cfgon data source 2. Define the same gscope ID,publicationsfor this data source, but with the paths that are relevant for the data source.gscopes.cfgpublications /pubs/ publications archive\.example\.co\.uk/releases/publications/To create a scope that spans across multiple data sources ensure you create gscopes using the same gscope ID in the different data sources. This will ensure all matched items are tagged with the same gscope ID. -
Run an advanced update on each data source, reapplying the gscopes.
-
Switch to your results page and edit the results page configuration. Add/edit the Query processor options key and add the gscope to the set of options:
Query processor options
-gscope1=publications <OTHER QUERY PROCESSOR OPTIONS>
Scoping search results to items that have URLs that match a metadata constraint or the set of items returned by a query
Scoping based on a metadata constraint or set of items returned by a query also uses gscopes, but uses the query gscopes configuration.
-
For metadata, ensure that the metadata field is mapped within your data source.
-
Add/edit
query-gscopes.cfgfor the data source and define the search query that defines the set of results that will be searched within. For metadata the query should be a metadata query (for example,type:publications). -
Run an advanced update of the data source to reapply gscopes.
-
Edit your results page configuration and add/edit the query processor options to include a
-gscope1parameter set to the gscope you defined in the previous step.
As this also uses the gscopes mechanism to tag relevant URLs you can use both URL type matching (in gscopes.cfg) and query-based matching (in query-gscopes.cfg) and have items added to a common gscope ID from both files - i.e. use the same gscope ID in both the configuration files. For example, I want to search over everything from the /publications/ folder (defined in gscopes.cfg) and everything that has a metadata type=publications (set in query-gscopes.cfg).
|
Scoping using the scope query processor options
| This option should only be used on small indexes as is a much slower way of scoping the index. |
The scope options also allow you to scope based on URLs, but this doesn’t require any additional configuration for the indexes. The trade-off is that the scoping is applied at the time the query runs and this process is much less efficient than using gscopes which are pre-calculated when the index is built.
To apply the scope:
-
Edit the results page configuration and add/edit the query processor options to add the
-scope,-lscopeor-xscopeoption.
Tutorial: Define a scope for a results page
When a new results page is created it has the same content as the parent search package.
Results pages are commonly used to provide a search across a sub-set of content within the search package. To achieve this the results page should be configured to apply a default scope.
In this exercise the Shakespeare search results page will be scoped so that only URLs from the Shakespeare website are returned when the running searches using the Shakespeare search results page.
The Shakespeare search results page is selected by passing a profile parameter set to the results page ID (shakespeare-search) in the search query.
-
Log in to the search dashboard where you are doing your training.
See: Training - search dashboard access information if you’re not sure how to access the training. Ignore this step if you’re treating this as a non-interactive tutorial. -
Locate the library search package.
-
Create another results page, but this time call the results page Shakespeare search.
-
Run a search for dream ensuring the preview option is selected and observe that pages from both the Shakespeare and Austen sites are returned.
-
Select edit results page configuration from the customize section. The index can be scoped by setting an additional query processor option.
Query processor options are settings that can are applied dynamically to a Funnelback search when a query is made to the search index. The options can control display, ranking and scoping of the search results and can be varied for each query that is run. -
Add a query processor option to scope the results page - various options can be used to scope the results page including
scope,xscope,gscope1andclive. Thecliveparameter is a special scoping parameter that can be applied to results page to restrict the results to only include pages from a specified data source or set of data sources. The clive parameter takes a list of data source IDs to include in the scoped set of data. Add acliveparameter to scope the results page to pages from the training~ds-shakespeare data source then click the save button, (but do not publish) the file. You can find the data source ID in the information panel at the top of the results page management screen.-clive=training~ds-shakespeare
-
Rerun the search for dream against the preview version of the Shakespeare search results page and observe that the results are now restricted to only pages from the Shakespeare site.
-
Rerun the search for dream against the live version of the Shakespeare search results page. Observe that pages are returned from both sites - this is because the query processor options must be published for the changes to take effect on the live version of the results page.
-
Edit results page configuration again, and publish the query processor options to make the setting affect the live version of the results page.
-
Rerun the search for dream against the Shakespeare search results page. Observe that pages are now restricted to Shakespeare site pages.