Web data source
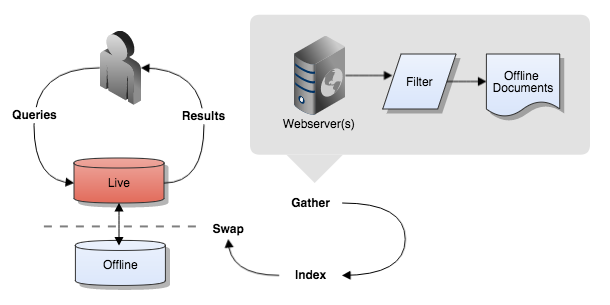
A web data source is a set of documents obtained from one or more web sites. Web data sources contain HTML, PDF and Microsoft Office files that are gathered using a web crawler which discovers content by following the links it finds.
In order to avoid crawling the entire Internet the crawler uses a number of data source configuration options to determine which links it will follow and what web sites or domains it should limit its crawl to.
Web data source basics
The web crawler works by accessing a number of defined URLs in the seed list and extracting the links from these pages. A number of checks are performed on each link as it is extracted to determine if the link should be crawled. The link is compared against a set of include/exclude rules and a number of other settings (such as acceptable file types) determining if the link is suitable for inclusion in the index. A link that is deemed suitable is added to a list of un-crawled URLs called the crawl frontier.
The web crawler will continue run taking URLs off the crawl frontier, extracting links in the pages and checking the links against the include/exclude rules until it runs out of links in the crawl frontier, or an overall timeout is reached.
One web data source or many?
As a general rule using as few data sources as possible as this has a number of benefits:
-
Maximizes ranking opportunities (as cross-site links will be included in the ranking).
-
Fewer updates to schedule which has a lower resource footprint on the server.
-
Allows more repositories to be added to a search package (as search packages have a limit on the number of data sources that can be included (and any push data sources that are included also eat into this limit as they are structured in a similar way to a search package).
Create another web data source:
-
If the data sources need to be updated on different update cycles (for example, a news section of a site updated every 30m, the rest of the site every 24h).
-
If the data sources contain internal and external content and these should be separated because they are used in different search packages (for example, a public search including an internet web data source and an internal search containing intranet sites and the public sites).
-
If the site has NTLM authentication (only a single NTLM username and password can be specified on a web data source).
sites with basic HTTP authentication can specify username and password per domain using site profiles ( site_profiles.cfg); and sites using form-based authentication can specify the settings using form interaction.
How does the crawler extract links to follow?
The crawler has two methods of performing link extraction.
-
The default method compares the URL to a link extraction pattern to determine if the link should be extracted. This pattern can be changed and the default is to extract links from within href and src attributes of elements. This method is great when you are working with web content.
-
An alternate method of link extraction will grab anything in text that looks like a URL and extract it as a link to follow. This method is useful when working with non-HTML content.
| Any link that is extracted will still be compared to the include/exclude patterns. |
Control what is included and excluded
Including:
-
robots.txt, robots meta tags,sitemap.xmland Funnelback noindex tags. -
include/exclude URL patterns.
-
crawler non-html extensions.
-
parser mime types.
-
download and parser file size limit.
-
crawl depth limits.
Use site profiles to limit multi-site crawls
Site profiles can be used to set various limits and also specify HTTP basic authentication to use when crawling specific domains.
Web data source optimization
Perform a post-crawl analysis
Perform a post-crawl analysis that investigates various crawl logs while a web data source is under development, and periodically after the collection is live.
-
Look at the
url_errors.logto see if there are common patterns of URLs that should be excluded from the crawl. -
Look at the
url_errors.logto see if there are files larger than thecrawler.max_download_sizethat should be stored. -
Look at the tail of the stored.log to see if the crawler is getting into any crawler traps that can avoided by defining exclude patterns, of if there are other things being stored that shouldn’t be.
-
Look at the
crawl.log.*files to see if any crawler trap prevention has been triggered.
Optimize settings
There are many settings that can be used to optimise the web crawler, that set various timeouts and limits.
If the site has a large number of domains then crawl speed can be increased if the number of crawler threads is increased as this sets an upper limit on the number of sites that can be crawled concurrently (the default is 20). Note: be sure to monitor how this affects the server performance as more threads will use more CPU. It may be necessary to increase the number of CPUs available to your Funnelback server.
If a site that is being crawled is sufficiently resourced then the site profiles can be used to specify multiple concurrent requests against the site (but be sure to get permission from the site owner first).
Creating a web data source
Web data sources require at a minimum a set of seed URLs and include/exclude patterns to be defined when setting up the data source.
To create a new web data source:
-
Follow the steps to create a data source, choosing web as the data source type.
See: Include and exclude patterns for information about defining what should be included (and excluded) from a web crawl.