Document filtering
Filtering is the process of transforming gathered content into content suitable for indexing by Funnelback.
Filtering passes the raw document through multiple chained filters which may modify the document in different ways. These modifications may include converting the document from a binary format such as PDF to an indexable text format or modifying the document by adding metadata or altering the document’s URL.
Filtering is run during the gather phase of a data source update. For the push data sources, the filter.classes provided in the data source configuration will be applied. This will be overridden if the filter parameter is set when the API is called.
| A full update is required after making any changes to filters as documents that are copied during an incremental update are not re-filtered. Full updates are started from the data source advanced update screen. |
Generic document and HTML document (jsoup) filters
Funnelback supports two main types of filters:
-
Generic document filters operate on the document as a whole taking the complete document as an input, applying some sort of transformation then outputting complete document which can then be fed into another filter. A generic document filter treats the document as either a binary byte stream, or as an unstructured blob of text.
-
HTML document filters (jsoup filters) are special filters that apply only to HTML documents. A HTML document filter handles the HTML as a structured object allowing precise and complex manipulation of the HTML document. HTML document (jsoup) filters are only run when the
JSoupProcessingFilterProvideris included in the filter chain.
The filter chain
The filter chain specifies the set of generic document filters that will be applied to a document after it is gathered prior to indexing. The contents of the gathered document passes through each filter in turn with the modified output being passed on to the input of next filter.
A typical filter chain is shown below. A binary document is converted to text using the Tika filters. This extracts the document text and outputs the document as HTML. This HTML is then passed through the JSoup filter (see the HTML document filters section below) which enables targeted modification of the HTML content and structure. Finally a custom filter performs a number of modifications to the content.

Each filter is represented by a Java class name, with filters separated by either a comma or semicolon to denote a choice or chain (see below).
The filters that make up the chain are chosen from:
-
Built-in filters: filters that are part of the core Funnelback product.
-
Plugins: filters that are provided by enabling specific Funnelback plugins.
-
Custom Groovy filters: User-defined Groovy filters that implement custom filter logic. (Not available in the Squiz DXP)
Filter chain steps
The filter chain is made up of a series of chained filtering steps which are executed in order with the output of the first step in the chain being fed into the second step in the chain.
Each step in the chain must specify one or more filters. If more than one filter is specified then a choice is made between the specified filters and up to one of these filters will be run. Note: it’s possible that none of the filters will match execution rules in which case the document content is passed through unchanged to the next filter in the chain.
For the filter chain represented graphically below:
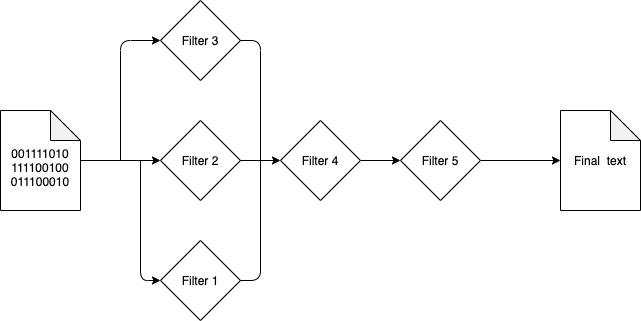
The binary input content would pass through either Filter3, Filter2, Filter1 or none of these (in that order) before passing through Filter4 and Filter5.
|
Configuring the filter chain
During the filter phase the document passes through a series of generic document filters with the modified output being passed on to the next filter. The series of filters is referred to as the filter chain, and is set using the filter.classes configuration option.
To modify the filter chain:
-
Log in to the search dashboard.
-
Locate the data source where the filters are to be applied and view the data source details screen.
-
Select edit data source configuration from the configuration section.
-
Edit the
filter.classesconfiguration option. This is located in the workflow section of the configuration key editor and will also be displayed in the currently set keys section if the option has been modified from the default value.
|
For example the default filter chain has three steps which run the following built-in filters:

-
Shows a set of choices: run an external filter or Tika (in that order) to convert a binary document to text. Note the comma that is used to delimit the two filters.
-
The steps of the filter chain. Each step is on a new line, with the filters being chained in the order defined from top to bottom. This configures Funnelback to choose between the external filter or Tika, then pass the extracted text through the jsoup filter (which manipulates HTML documents). The default jsoup filters run a number of content auditing tasks. See: HTML document (jsoup) filters. Finally, pass the manipulated HTML document through the document title fixer.
|
If you use the raw configuration key editor to set the filter.classes=TikaFilterProvider,ExternalFilterProvider:JSoupProcessingFilterProvider:DocumentFixerFilterProvider |
Built-in filters
Funnelback ships with the following built-in filters.
Configure Funnelback to use a built-in filter by adding the class name to the filter.classes.
For example: filter.classes=ForceCSVMime:CSVToXML replaces the default filter chain with the two built-in filters for handling CSV indexing.
| Filter | Description |
|---|---|
Use this built-in filter to convert records in a CSV, TSV, SQL or Excel document into multiple XML documents. |
|
Use this built-in filter to convert JSON documents into XML. |
|
Use this built-in filter to replace poor HTML document titles. The filter analyzes the document title and attempts to replace it if the title is not considered a good title. HTML documents only. |
|
(deprecated) Use this built-in filter to convert documents using an external converter program. |
|
Use this built-in filter to force all documents to be processed with an assigned |
|
Use this built-in filter to force all documents to be processed with an assigned |
|
Deprecated. Use the Force XML plugin. Do not use. Previously this built-in filter was used to force all documents to be processed with an assigned |
|
Use this built-in filter to force all documents to be processed with an assigned |
|
Use this built-in filter to remove headers/footers and navigation from your search results by automatically inserting noindex tags into HTML documents based on CSS selectors. |
|
Use this built-in filter to enable the transformation of HTML documents using a set of Jsoup filters that operate on the HTML document structure. |
|
Use this built-in filter to add additional metadata, extracted from HTML and XML document content. |
|
Use this built-in filter to clean, transform and normalize metadata values. |
|
Use this built-in filter to convert binary files of specific file formats (Microsoft Office files, PDF files, etc.) into HTML using Apache Tika. |
|
Use this built-in filter to detect if a URL contains textual content. Used by the Content Auditor. |
|
(deprecated) Used for generic filtering workflows (for example, inserting metadata based on URL patterns, performing string replacements, etc.) |
|
Use this filter to detect the content generator for a HTML page. |
|
Use this filter to analyze the reading grade level of a HTML page. |
|
Use this filter to analyze HTML page content for undesirable text. |
|
Use this filter to detect HTML pages containing duplicate titles. |
Using custom filters
Funnelback plugins can provide additional filters. When using a plugin always follow the instructions as outlined in the plugin’s readme file.
Configure Funnelback to use a filter that is included as part of a plugin by:
-
Adding the class name as detailed in the plugin’s readme to the
filter.classes.
For example: Add the example plugin custom filter with class name com.example.customPluginFilter to the default filter chain:

This runs the filters as defined in the default filters section (above) then feeds the document (with fixed title) into the custom plugin filter.