Integration flows
An integration flow is an automated workflow used to synchronize data between multiple applications or services. Typically a flow consists of following:
- Components
-
An integration component is a small application specialized in retrieving/storing objects from/to a service such as Salesforce, Quickbooks, SAP, or similar. Every step in a flow contains a component which consumes input, connects a service, produces output.
- Trigger
-
A trigger is the first step in any flow.
- Actions
-
Every step in the flow after the trigger is an action. It transforms or otherwise actions the data taken by the trigger.
Every flow starts with a single trigger that takes data from an external source and produces output to be used by the next step in the flow. The trigger is the single source of data for a flow.
All of the other steps in a flow are used to transform that data, and action it. These actions may include sending data to other components, sending emails or simple HTTP responses.
The following diagram shows a single Trigger resulting in multiple actions.
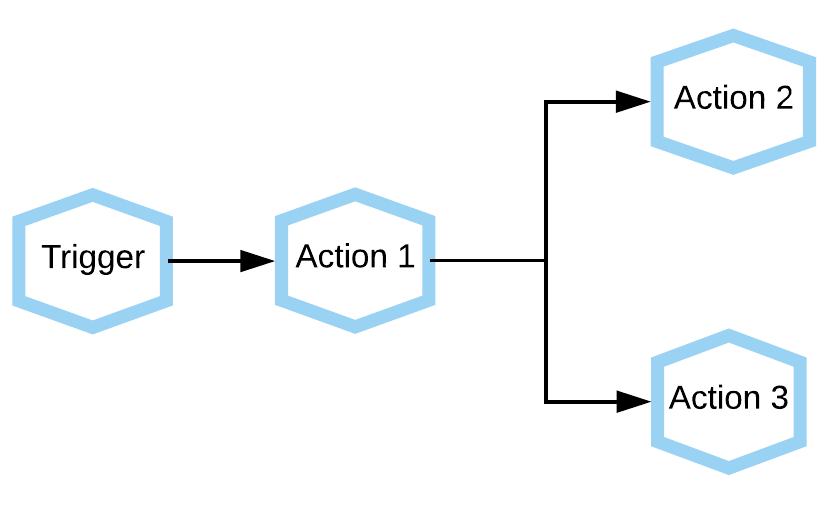
For example the flow above may represent something the the following:
- Trigger
-
a webhook is used to get data from a web form (for example, a customer registers interest in a service)
- Action 1
-
The data is transformed so that it can be pushed to a CMS.
- Action 2
-
The data is pushed to the CMS.
- Action 3
-
An email is sent to inform a key group that new data has been added to the CMS.
Flow actions
The data produced by a trigger component are sent to an action component for transformation or consumption. For example, a new object from Salesforce may be sent straight to Quickbooks for insertion or update, or it may be sent to an intermediate Action component such as a Transformation to reformat the data so that Quickbooks can accept it.
After consuming the incoming data, an action may produce further new data which can be consumed by the next action.
Containers and queues
Each step of an integration flow runs as an individual Docker container. These containers are connected through a messaging queue, as shown in the following diagram:
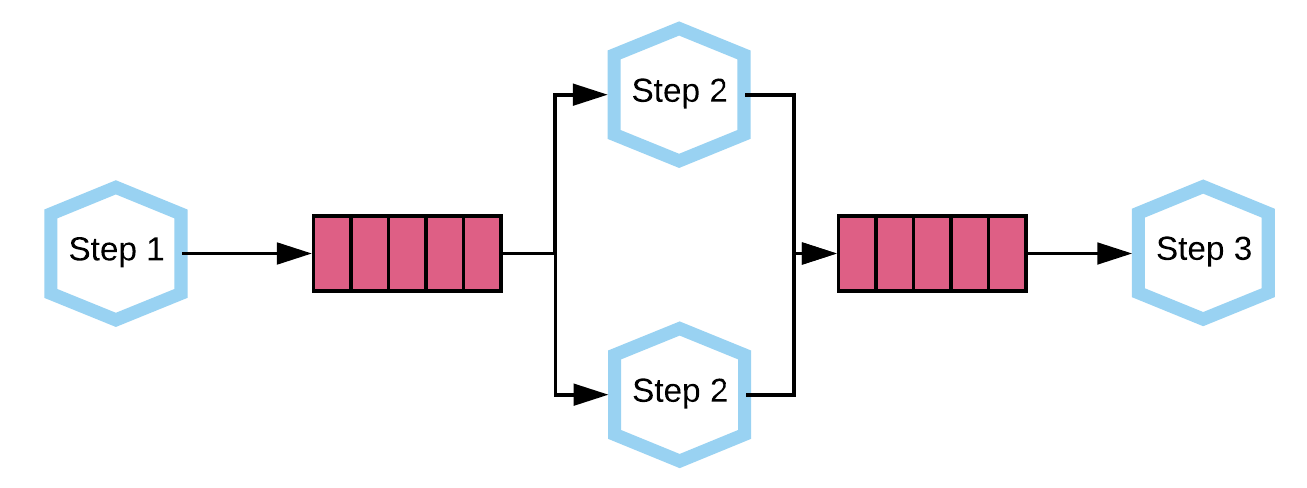
This architecture has a number of advantages:
-
Data is never lost if any of the containers crash.
-
Containers can be scaled if needed to parallelise the work, for example, in the diagram above we have two instances of Step 2 running.
-
Reliable message delivery between containers, for example, when the target API is unavailable the platform can easily retry later as the messages remain on the queues.